1 آزمایش اول: آشنایی با نرم افزار ISE و مراحل پیادهسازی کد VHDL
روی FPGA
هدف از این آزمایش، آشنایی با نرم افزار ISE میباشد. نرم
افزار ISE از شرکت Xilinx است که برای شبیهسازی، سنتز و پیادهسازی برنامههای نوشته شده به
زبانهای توصیف سخت افزار قابل استفاده است. اصولا هر شرکت تولید کننده FPGA باید نرم
افزاری جهت پیادهسازی کدهای توصیف سخت افزار داشته باشد.
برای پیادهسازی یک مدار
روی FPGA
مراحل زیر مورد نیاز است:
الف) طراحی مدار
ب) توصیف مدار با زبانهای
توصیف سخت افزار
ج) شبیهسازی
د)سنتز
ه)پیادهسازی
در مرحله طراحی، با توجه به صورت مساله و ورودی/خروجیهای سیستم، روشی
برای تولید خروجیها بر اساس ورودیها ارائه میشود(روشهای مختلف طراحی در درس
طراحی خودکار سیستمهای دیجیتال ارائه میشود) سپس با به طراحی انجام شده، برنامه VHDL نوشته میشود
و در مرحله سنتز، برنامه نوشته شده به زبان VHDL به المانهای
دیجیتال نظیر فلیپ فلاپ، حافظه، دیکدر، مالتی پلکسر و ... تبدیل میشود و نهایتا
در مرحله پیادهسازی، کدهای سنتز شده با المانهای موجود در FPGA جایگزین و
فایل نهایی برای پراگرام کردن FPGA آماده میشود.
برای سنتز و پیادهسازی برنامه VHDL، نرم افزارهای مختلفی وجود دارد. با
توجه به اینکه در طراحی بوردهای آزمایشگاه، از FPGAهای شرکت Xilinx استفاده شده است بنابراین از نرم افزار تولید شده شرکت زایلینکس
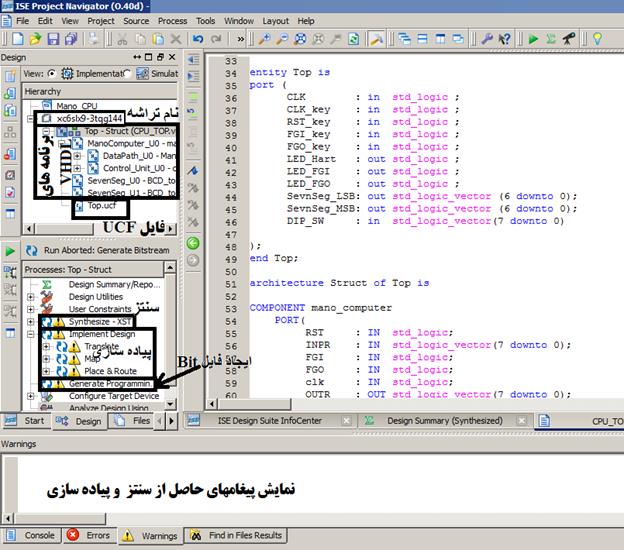
برای سنتز و پیادهسازی کدهای VHDL نوشته شده استفاده میکنیم. در شکل 1-1، شکل ظاهر این نرم افزار
نمایش داده شده است. در این شکل، قسمتهای مختلف این نرم افزار مشخص شدهاند.
هنگام ایجاد یک پروژه جدید در این نرم افزار، باید نام خانواده FPGA، نام قطعه،
نوع بسته بندی انتخاب گردد. مثلا FPGAهای استفاده شده در
بوردهای آزمایشگاه از خانواده Spartan6 هستند و نام قطعه 6SLX9
ونوع بسته بندی تراشه TQG144 میباشد(تراشه از نوع چهارطرفه و دارای 208 پایه).
بعد از اینکه در این نرم افزار پروژه خود را ایجاد کردید نام تراشه به صورت اختصار
در قسمت فوقانی پنجره مینویسد. تراشه ای که در شکل 1-1 استفاده شده است xc6slx9-3tqg144 میباشد که حاوی تمام اطلاعات تراشه مورد نظر میباشد.
شکل 1-1: قسمتهای مختلف
نرم افزار ISE
بعد از ایجاد پروژه و اضافه کردن فایلها به آن، با دابل کلیک کردن روی
گزینه Synthesize، عملیات سنتز شروع میگردد. گزارش مربوط به سنتز کردن را در پنجره
console
(قسمت پایینی پنجره) نمایش میدهد. در صورت موفقیت آمیز بودن عملیات سنتز، میتوان
گام بعدی که پیادهسازی طرح باشد را شروع کرد. برای شروع عملیات پیادهسازی باید
روی گزینه Implement Design دابل کلیک کنید. همانطور که در شکل 1-1 مشاهده میشود عملیات پیادهسازی
از سه گام به نامهای Translate، Map و Place &
Route تشکیل شده است. برای ایجاد فایل
نهایی باید روی گزینه Generate
Programming… دابل کلیک کنید.
برای پراگرام کردن FPGA میتوان مستقیما روی گزینه Configure Target Device
دابل کلیک کرد یا اینکه از نرم افزار Impact استفاده کرد. این نرم افزار جزء مجموعه ISE است و به
صورت اتوماتیک هنگام نصب نرم افزار ISE، نصب میگردد.
اصولا در سیستمهای دیجتال برای اینکه نشان داده شود سیستم زنده و در
حال کار میباشد، یک LED روی بورد مربوطه تعبیه میشود و با روشن شدن سیستم، این LED با روشن و
خاموش شدن متوالیش، زنده بودن سیستم را نشان میدهد. در این قسمت قصد داریم به
عنوان اولین آزمایشی که با بوردهای آزمایشگاه انجام میدهیم یک مدار چشمک زن را پیادهسازی
کنیم.
برنامه VHDL مورد نیاز برای یک LED چشمک زن به صورت زیر است
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
USE ieee.std_logic_unsigned.all;
entity BlinkingLED is
Port (
Clk : in STD_LOGIC;
Led : out STD_LOGIC
);
end BlinkingLED;
architecture Behavioral of BlinkingLED is
signal delay_counter: std_logic_vector(31 downto 0);
begin
Led <= delay_counter(24);
process(Clk)
begin
if(Clk='1' and Clk'event)then
delay_counter<=delay_counter+1;
end if;
end process;
end Behavioral;
1- نرم
افزار ISE را
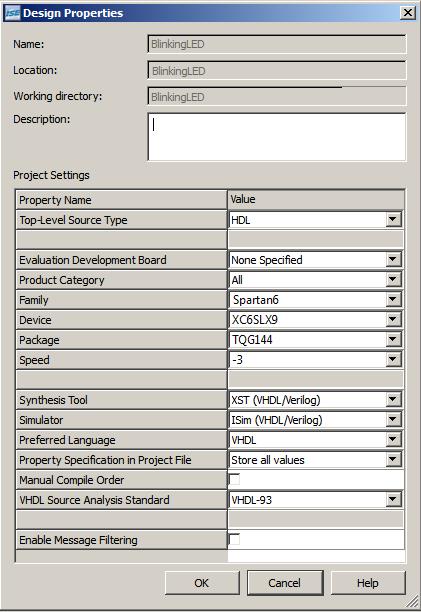
طبق صحبتهای انجام شده در آزمایشگاه، نصب کنید. سپس با انتخاب گزینه New Project … از
منوی File، یک
پروژه جدید به نام BlinkingLED ایجاد کنید( تنظیمات مورد نیاز در شکل 1-2 نشان داده شده است)
2-
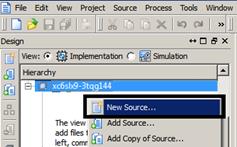
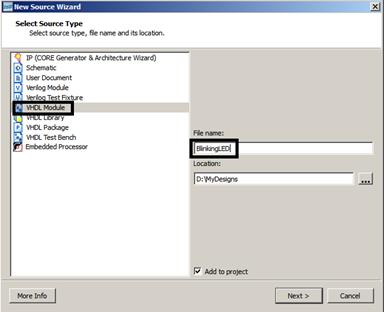
یک فایل جدید ایجاد کنید و برنامه نوشته شده در قسمت پیش
گزارش را در آن کپی کنید. برای ایجاد یک فایل جدید باید روی اسم تراشه(در پنجره
سمت چپ)، کلیک راست نموده و گزینه New
Source… را انتخاب کنید سپس در پنجره ظاهر
شده، گزینه VHDL Module را انتخاب کنید و نام فایل را نیز در قسمت مربوطه بنویسید.(مراحل انجام
آن در شکلهای 1-3 و 1-4 نشان داده شده است)
3-
برنامه را سنتز کنید و مشاهدات خود از خروجی سنتز (پنجره
کنسول که در شکل 1-1 نشان داده شده است) را بنویسید.(تعداد فلیپ فلاپها، بلوکهای
تشخیص داده شده در کد VHDL و Warningها) (جواب این سوال را
روی کاغذ بنویسید و به صورت حضوری در آزمایشگاه تحویل دهید)
 .
.
شکل 1-2: تنظیمات مربوط
به تراشه مورد استفاده در بوردهای آزمایشگاه
شکل 1-3: نحوه ایجاد یک
فایل جدید
شکل 1-4: انتخاب فایل VHDL و نامگذاری
آن
1- در
نرم افزار ISE یک پروژه جدید به نام BlinkingLED ایجاد کنید
تراشه را XC6LXو پکیج آن را TQG144 انتخاب کنید.
2- برنامه
VHDLی بنویسید که فرکانس کلاک ورودی
را که 50مگاهرتز است را به 1 هرتز تبدیل کند.
3-
برنامه را سنتز کنید و مشاهدات خود از خروجی سنتز (پنجره
کنسول که در شکل 1-1 نشان داده شده است) را بنویسید.(تعداد فلیپ فلاپها، بلوکهای
تشخیص داده شده در کد VHDL و Warningها)
4-
برای برنامه فوق یک فایل UCF بنویسید به
نحوی که پایه کلاک را به اسیلاتور روی بورد متصل و سیگنال 1 هرتز را به LED روی بورد
متصل کند.
5-
بیت فایل را ایجاد کنید و با کمک نرم افزار impact آن
را روی بورد پراگرام کنید و نتیجه را به مسئول آزمایشگاه نشان دهید.
2 آزمایش دوم: راه اندازی دکمههای فشاری و دیودهای نورانی روی
بورد FPGA
هدف از این آزمایش، کار با دکمههای فشاری روی بورد آموزشی میباشد.
بعد از اینکه برنامه VHDL نوشته شد و شبیهسازی آن به اتمام رسید، برای پیادهسازی نهایی آن
روی سخت افزار، باید فایلی را آماده کرد که پورتهای Entity نوشته شده
را به پایههای تراشه FPGA مپ کند. به این فایل اصطلاحا ucf (User Constraint File)
گفته میشود. فرمت این فایل به صورت زیر است:
NET "CLK25M" LOC = "AA14" |
IOSTANDARD = LVTTL ;
سطر فوق به این مفهوم است که سیگنال CLK25M که در
برنامه VHDL
استفاده شده است (یکی از پورتهای Entity است) به پایهای به نام AA14(نام پایهها را باید از کاتالوگ
تراشه FPGA
استخراج کنید) متصل شود و استاندارد ولتاژ آن پایه نیز LVTTL است.
1- با
استفاده از شماتیک بورد آزمایشگاه، به سوالات زیر پاسخ دهید:
الف) چند عدد دکمه فشاری روی بورد
وجود دارند؟ نام آنها را یادداشت کنید؟
ب)کدام یک از دکمههای فشاری
مستقیما به پایههای FPGA متصل هستند؟ شمارههای پایه FPGA را نیز
مشخص کنید.
2-
به برنامه جلسه گذشته یک پورت جدید به نام Enable
اضافه کنید. عملکرد این پایه به این صورت است که اگر مقدار آن "1" باشد
آنگاه، LED
چشمک زن باشد و اگر مقدار آن "0" بود آنگاه LED خاموش شود.
3- برای
برنامه فوق، یک فایل ucf ایجاد کنید و با توجه به شماتیک بورد، پایههای مناسب را به
پورتهای Entity خود اضافه کنید.
4-
بیت فایل را ایجاد کنید و با کمک نرم افزار impact آن
را روی بورد پراگرام کنید و نتیجه را به مسئول آزمایشگاه نشان دهید
5-
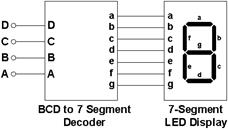 برنامهای به زبان VHDL بنویسید که
یک عدد BCD
دریافت کند و معادل 7seg آن را
تولید کند.
برنامهای به زبان VHDL بنویسید که
یک عدد BCD
دریافت کند و معادل 7seg آن را
تولید کند.
6-
با استفاده از دستور for generate، یک جمع
کننده 512 بیتی را با استفاده از Full
Adder پیادهسازی کنید.
هدف از این آزمایش، آشنایی با مباحث تاخیر و فرکانس کلاک در FPGA میباشد. در این آزمایش به عنوان نمونه، نحوه محاسبه تاخیر یک جمع کننده
32 بیتی آزمایش میگردد.
یکی از سوالهای مهم در هنگام پیادهسازی یک مدار دیجیتال با استفاده از
FPGA، این
است که مدار پیادهسازی شده حداکثر با چه فرکانسی کار خواهد کرد. یا اگر مدار به
صورت ترکیبی باشد آنگاه تاخیر این مدار ترکیبی چقدر خواهد بود.
برای محاسبه تاخیر و حداکثر فرکانس کلاک در مدارهای ترتیبی کافی است در
فایل ucf، یک
محدودیت برای سیگنال کلاک تعریف شود. اگر فرض کنیم CLK نام سیگنال
کلاک باشد آنگاه با اضافه کردن دو دستور زیر در فایل ucf، به نرم
افزار اعلام میکنیم که قصد داریم به پریود کلاک برابر 3 نانوثانیه برسیم.
NET "CLK" TNM_NET = "SYS_CLK";
TIMESPEC "TS_SYS_CLK" = PERIOD
"SYS_CLK" 3 ns HIGH 50 %;
نرم افزار ISE سعی میکند در مراحل map و place and route، زمان ذکر شده در فایل ucf را برآورده کند. در نهایت تاخیرها و
فرکانس کلاک دست یافتنی را در گزارش place
and route ارائه میدهد. این گزارش در فایلی
با پسوند par
ذخیره میشود.
(گزارش مربوط به مرحله سنتز در فایلی با پسوند syr و گزارش
مربوط به مرحله MAP در فایلی با پسوند map ذخیره میشود)
برای دیدن پارامترهای زمانی طرح ایمپلیمنت شده میتوان از طریق دابل
کلیک روی & Route Static Timing Analyze Post-Place از
زیر مجموعه Place & Route اقدام کرد. در شکل 3-1، محل این گزینه نمایش داده
شده است.
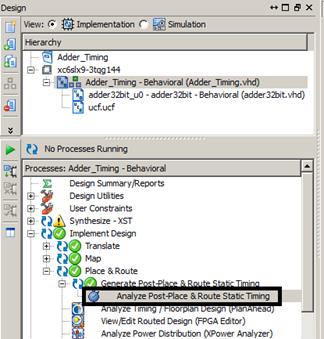
شکل 3-1: نحوه بررسی
نتایج زمانی مربوط به ایمپلیمنت طرح
برای محاسبه تاخیر در مدارهای ترکیبی، میتوان ورودیها و خروجیهای
طرح را رجیستر و مدار را به یک مدار ترتیبی تبدیل کرد. سپس مدار ترتیبی بدست آمده
را مشابه روش ذکر شده در بخش 3-1-1 تحلیل زمانی کرد.
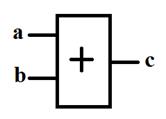
به عنوان مثال فرض کنید یک بلوک جمع کننده به صورت نمایش داده شده در
شکل 3-1 را در اختیار داریم.
|
|
|
|
شکل 3-1: یک جمع کننده
که به صورت ترکیبی پیادهسازی شده است.
|
شکل 3-3: اضافه کردن
رجیستر به ورودیها و خروجیهای جمع کننده
|
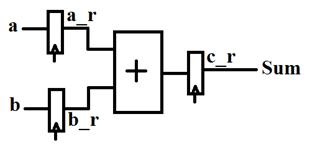
برای بدست آوردن تاخیر این جمع کننده باید یک فایل جدید ایجاد شود و
مدار نمایش داده شده در شکل 3-3 در آن پیادهسازی گردد. همانطور که در شکل ملاحظه میگردد،
با اضافه کردن سه رجیستر به نامهای a_r، b_r و c_r مدار نمایش داده شده در شکل 3-1 به یک مدار ترتیبی تبدیل شده است.
در شکل 3-4، برنامه مربوط به مدار شکل 3-3 نمایش داده شده است.

شکل 3-4: برنامه VHDL مربوط به
مدار نمایش داده شده در شکل 3-3
بعد از اتمام مرحله Place
& Route، دوره تناوب بدست آمده برای کلاک را
میتوان در فایل با پسوند par مشاهده نمود. همانطور که در شکل 3-5 نشان داده شده است، دوره
تناوب کلاک میتواند حداقل 2.539ns
باشد. این نکته به این مفهوم است که تاخیر جمع کننده برابر با 2.539ns است.

شکل 3-5: قسمتی از نتیجه Place & Route که
حاوی اطلاعاتی در مورد Constraint قرار داده شده برای کلاک میباشد.
7-
تاخیر یک جمع کننده 32 بیتی را برای تراشههای مختلف XC6SLX4 و XC6SLX9 را
بدست آورید
8-
با تغییر تعداد بیتهای جمع کننده رابطه بین تعداد بیتها و
میزان تاخیر را در تراشه XC6SLX9 را بدست آورید.
9-
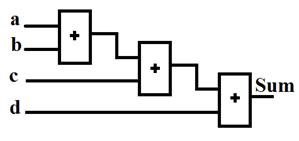
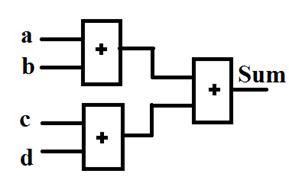
تاخیر دو مدار زیر را برای محاسبه جمع چهار عدد 32 بیتی
بدست آورید
هدف از این آزمایش، آشنایی با Coreهای
سخت افزاری و نحوه تولید آنها توسط نرم افزار ISE میباشد.
COREها، برنامههای آماده و
سنتز شده ای هستند که میتوان از آنها در برنامههای VHDL استفاده
نمود. نکته ی اصلی اینجاست که امکان دسترسی به source code این برنامهها
وجود ندارد و تنها میتوان از آنها در برنامههای گوناگون استفاده نمود.
COREها به دو دسته تقسیم میشوند:
یک دسته از COREها، از قبل و به صورت
انحصاری توسط شرکتهای سازنده ی FPGA با توجه به ساختار داخلی آن، طراحی و عرضه میشود. مثلا برای
استفاده از حافظه ی داخلی یا میکروکنترلر تعبیه شده در FPGA میتوان از COREهای مخصوص آن استفاده
کرد. در اینجا کد VHDL واقعی وجود ندارد و در واقع Core به عنوان
یک wrapper
برای آن بلوک سخت افزاری میباشد.
دسته ی دوم، برنامههای عمومیای هستند که به زبان توصیف سخت افزار
نوشته و سنتز شدهاند و فایل سنتز شده ی آن عرضه میشود. مثلا برای ارتباط وسایل
جانبی با FPGA میتوان از این دسته COREها استفاده نمود. در اینجا کد VHDL، واقعا
وجود دارد ولی در دسترس نمیباشد. ( ممکن است شرکتهای سازنده ی FPGA، این دسته
از COREها را هم تولید نمایند.)
حداقل به دو فایل برای استفاده از COREها در برنامه ی VHDL نیاز است: فایل سنتز شده و Component
مورد استفاده (یعنی اطلاع از نام پورتها و مشخصات آنها)
استفاده از COREها در نرم افزار ISE را با یک
مثال پی میگیریم:
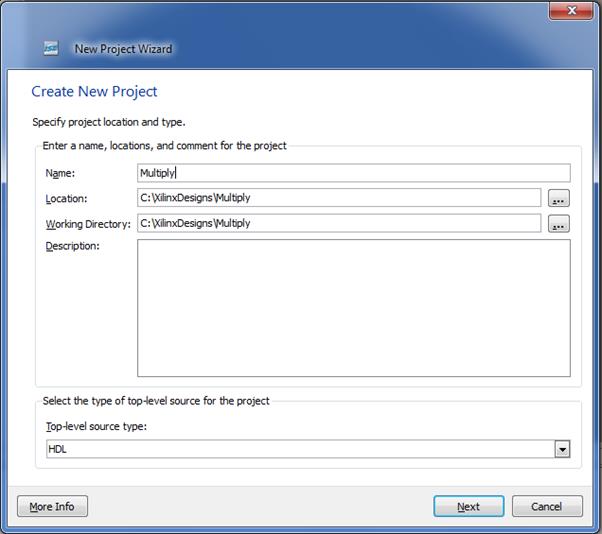
ابتدا یک پروژه ی جدید با نام Multiply ایجاد میکنیم:
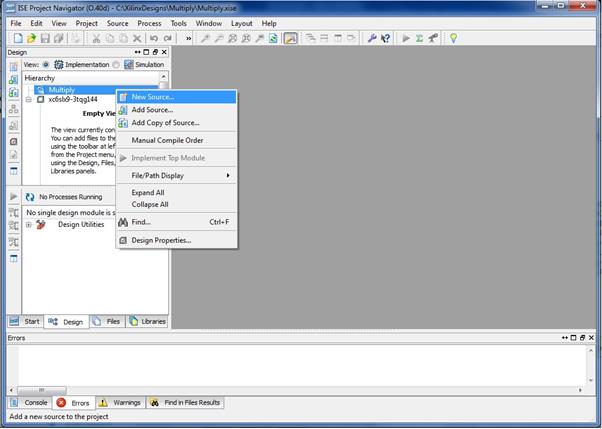
حالا در پروژه، روی گزینه ی New Source... کلیک میکنیم:
حال در صفحه ی باز شده، گزینه ی IP (CORE Generator & Architecture Wizard) را انتخاب میکنیم:

و Next را میزنیم؛ حال پنجره ی New Source Wizard باز میشود:
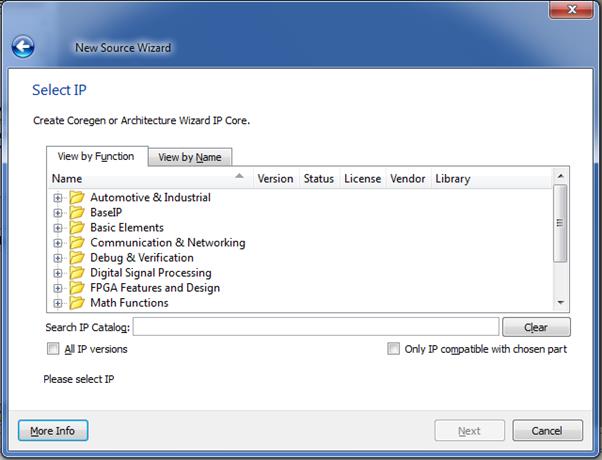
در اینجا فهرست کاملی از COREهای تعبیه شده در نرم
افزار وجود دارد که میتوان برای برنامههای گوناگون از آن استفاده نمود. در قسمت Search IP Catalog هم
میتوان CORE
مورد نظر را جستجو کرد.
در اینجا ما برای پیادهسازی یک ضرب کننده ی 8بیتی، از شاخه ی Math Functions، گزینه
ی Multiplier را
انتخاب میکنیم.

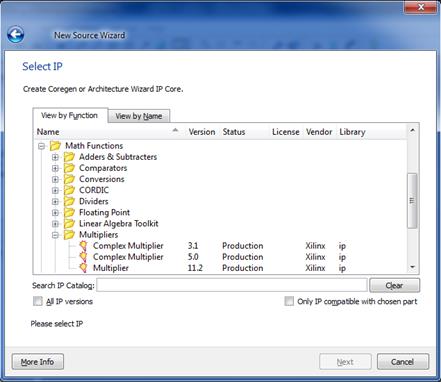
Next را میزنیم. حالا پنجره ی دیگری باز میشود که در
آن میتوان خصوصیات CORE انتخابی را مشاهده و مدیریت نمود:
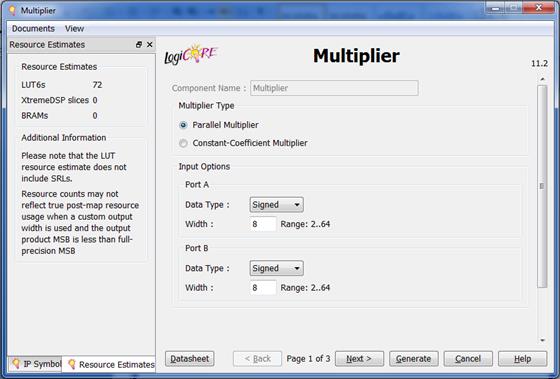
با انتخاب دکمه Datasheet میتوان به اطلاعات اصلی CORE دسترسی
یافت. در این مثال خاص میتوان مثلا اندازه ی هر یک از عناصر ضرب شونده (PORTA و PORTB) را تعیین نمود که در اینجا ما هر دو را 8بیتی در نظر میگیریم و
اعداد را علامتدار انتخاب میکنیم. و Next را میزنیم.
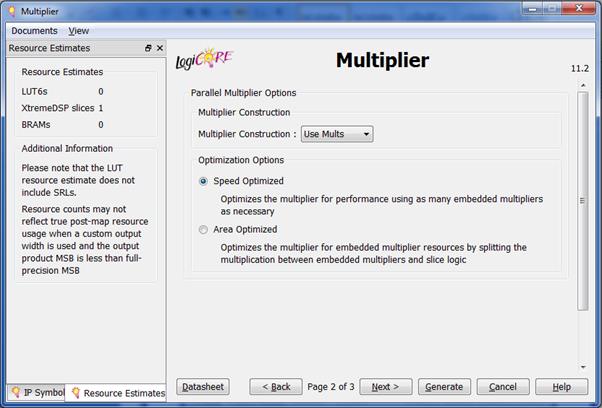
در این صفحه جدید میتوان خصوصیات دیگری را تنظیم نمود. مثلا در قمست Multiplier Construction میتوان تعیین کرد که پیادهسازی ضرب کننده چگونه باشد. ما در اینجا Use Mults را
انتخاب میکنیم. در این حالت پیادهسازی ضرب کننده به وسیله ی ضرب کنندههای داخلی
FPGA
انجام میپذیرد. در این پنجره، همچنین گزینههایی راجع به بهینه سازی وجود دارد.
دکمه ی Next را
میزنیم.
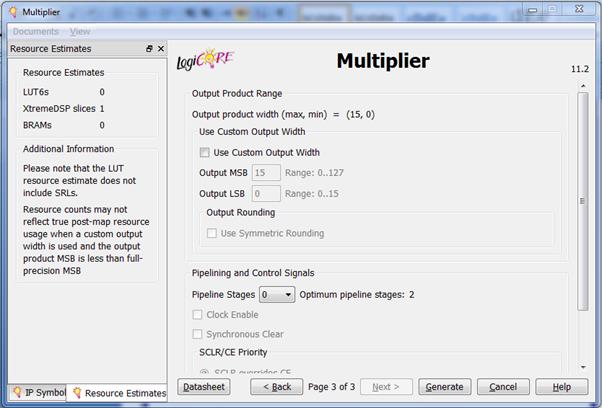
در پنجره آخر هم اطلاعاتی وجود دارد. مثلا میتوان اندازه ی خروجی ضرب
کننده را تعیین نمود که در اینجا با توجه به اندازه ی عناصر ورودی (8 بیتی)، اندازه
ی خروجی به طور پیش فرض 16 بیت در نظر گرفته شده که البته میتوان آن را تغییر
داد.
نهایتا دکمه ی Generate را میزنیم. همه ی فایلهای مورد نیاز در پوشه ای به نام ipcore_dir
قرار دارد. از مهمترین فایلهایی که در این پوشه ساخته میشود عبارتند از فایلی با
پسوند vho و
دیگری با پسوند veo. این دو فایل به ترتیب حاوی تعریف component و نحوه Port Map
کردن Core
ایجاد شده به زبانهای VHDL و Verilog میباشد.


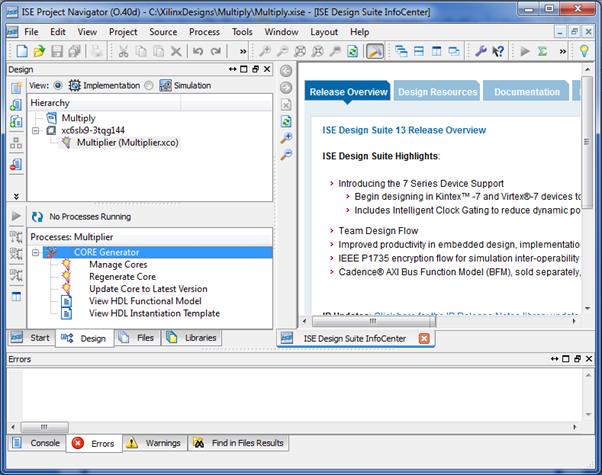
همچنین در پنجره ی پایینی، گزینه ی CORE Generator
ایجاد میشود که قسمتهای مختلفی را برای مدیریت و استفاده از CORE به دست میدهند.
هم اکنون فایل سنتز شده ی موردنیاز نیز به طور خودکار ایجاد شده است. همان طور که
گفته شد غیر از فایل سنتز شده به مشخصات پورتهای CORE نیز
نیازمندیم. این اطلاعات در قسمت View
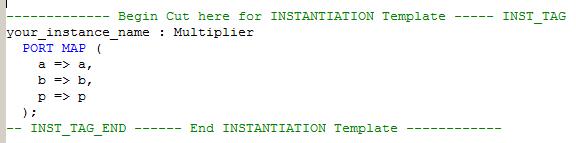
HDL Instantiation Template وجود دارد.
با دوبار کلیک کردن روی این گزینه، یک فایل متنی باز میشود که حاوی اطلاعات پورتها
برای افزودن Component و سپس Port Map کردن است:
حالا میتوان یک برنامه به زبان VHDL به صورت top module
نوشت و از CORE به عنوان یک Component استفاده کرد. به همین منظور یک فایل VHDL به نام top میسازیم و کد آن را به این صورت دستکاری میکنیم:
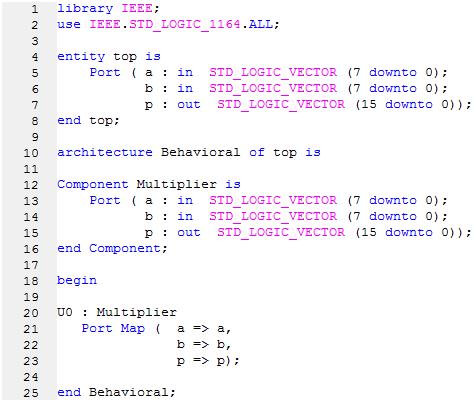
حالا میتوان با استفاده از یک برنامه Test Bench، برنامه ی
بالا را شبیهسازی نمود. اگر در برنامه TestBench دستورات زیر را قرار دهیم:
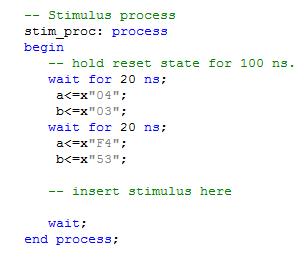
آنگاه نتیجه شبیهسازی به صورت زیر خواهد شد:
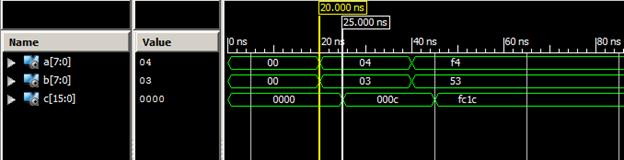
همان طور که در نتیجه شبیهسازی مشاهده میشود تاخیر ضرب کننده 5
نانوثانیه بوده و ضرب دو عدد 3 و 4 و همچنین ضرب اعداد 12- و 83 (در مبنای 10) را
به درستی انجام داده است.
10-با استفاده از Core ضرب کننده و
جمع کننده در نرم افزار ISE، مدار زیر را طراحی و شبیهسازی کنید.
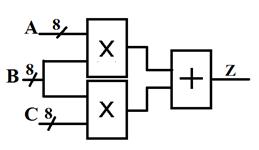
11-با اضافه کردن Constraint
برای کلاک، و اضافه کردن رجیستر در ورودی و خروجیهای مدار فوق، حداکثر فرکانس کلاک
برای مدار فوق را بدست آورید.
12-فایل ucf برای طرح
بالا ایجاد کنید و سپس اعداد را از طریق DIP switchهای روی بورد به سیستم اعمال کنید و نتیجه را روی 16 LED مشاهده
کنید و نتیجه را به مسئول آزمایشگاه نشان دهید.
5 آزمایش پنجم:
آشنایی با Block RAMها و
زمانبندی خواندن و نوشتن در آنها
5-1
پیش آگاهی
هدف از این آزمایش، آشنایی با Block Ramها
و نحوه
تولید آنها توسط نرم افزار ISE میباشد و زمانبندی خواندن و نوشتن در آن و شبیهسازی
آن میباشد. Block Ramها قطعات سخت افزاری هستند کهRam را پیادهسازی میکنند و در اکثر طرحهای
سخت افزاری به کار میروند که معمولا در اندازههای 2کیلو بایتی(18کیلو بیت) میباشند.
Block Ram یکی از اجزای اصلی FPGA است. در مشخصات FPGAها دو نوع Ram وجود دارد: Distributed Ram و Block Ram.
Distributed Ram حافظه
ی RAMاست که از کنار هم قرار دادن LUTهای FPGA ایجاد
میشود. در مواردی که بخواهیم از حافظههای کوچک استفاده کنیم به کار میرود.
ابتدا یک پروژه جدید با نام blkram_exe1 ایجاد میکنیم.
برای ایجاد یک block ram، باید یک core جدید ایجاد
کنیم. همانند آزمایش 4 مراحل زیر را تکرار میکنیم.
بر روی پروژه کلیک راست کرده و گزینه new source را انتخاب میکنیم.
در پنجره باز شده IP(CORE
Generator & Architecture Wizard) را انتخاب میکنیم
و نام core را
در قسمت file name
مینویسیم. در اینجا حافظه مورد نظر ما یک حافظه 1k*8bit است.
بنابراین نام حافظه را blkram1kx8bits قرار میدهیم.
در قسمت New Source Wizard، با
جستجوی عبارت memory، Block Memory
Generator را انتخاب میکنیم.
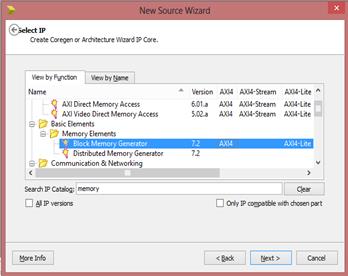
بلاک دیاگرام Ram در سمت چپ تصویر نشان داده شده که پایههای فعال و غیرفعال آن در
شکل مشخص شده است. در این حافظه پورت خواندن و نوشتن از یکدیگر مجزا هستند و به
همین دلیل به سیگنال کنترلی read نیازی ندارد. خواندن همیشه فعال است. آدرس را که قرار دهیم، Data پس از یک CLK برابر
محتویات آن خانه از حافظه میشود. به این صورت که Data همیشه یک CLK شیفت دارد.
اگر در یک CLK داده را قرار دهیم، در CLK بعدی میتوانیم داده را استفاده
کنیم.
در اینجا ما دو نوع Interfaceداریم: AXI وNative. اگر AXI را
انتخاب کنیم، Interface مستقیما بهAXI Busمتصل میشود که ما در
اینجا از آن استفاده نمیکنیم و Native را انتخاب میکنیم.
Memory Type:
با انتخاب هر یک از انواع حافظه زیر، پورتهای بلاک دیاگرام سمت چپ
تغییر میکند. Single Port Ram: فقط یک Busآدرس دارد. همزمان نمیتوان به خانههای
مختلف حافظه
دسترسی داشت
ولی میتوانیم در یک خانه از حافظه بنویسیم و بخوانیم.
True Dual
port: یک حافظه با دو پورت کاملا مجزا
است. ( پورت A و B)
Simple dual
port: پورت A امکان
خواندن و نوشتن را دارد ولی پورت B فقط امکان خواندن دارد.
Single port
Rom: یک مقدار اولیه به آن داده میشود
و همه از همان مقدار اولیه استفاده میکنند و دیگرنمیتوان در آن نوشت.
Dual port Rom: دو پورت آدرس دارد و امکان نوشتن ندارد.
در این مرحله Single
Port Ram را انتخاب میکنیم.
ECC(Error Correction
Code):
چون در حافظهها امکان خطا وجود دارد، به ازای هر 8 بیت، یک بیت اضافه میکند و parity را
در آن ذخیره میکند. گفتیم حافظهها معمولا 2کیلوبایتی هستند که برابر 16 کیلو بیت
است که با درنظرگرفتن دو بیت برای parity، 18کیلوبیت خواهیم داشت.
Byte Write Enable:
برای حافظههایی که بیشتر از 8 بیت عرض دارند، مشخص میکند که در یک
سطر کدام بایتها نوشته شوند.
در قسمت Algorithm نیز با توجه به هدف پروژه، یکی از سه مورد آن را انتخاب میکنیم.
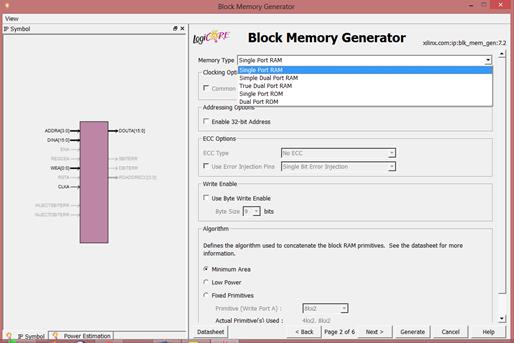
در اینجا میخواهیم یک حافظه 1k x 8bit را پیادهسازی کنیم.
بنابراین عرض داده را 8 بیتی و تعداد کلمات را 1024=  (10 خط آدرس)قرار میدهیم.
(10 خط آدرس)قرار میدهیم.
Operating Mode اولویتهای ReadوWrite را
مشخص میکند. ما در اینجا write first را
انتخاب میکنیم.
در قسمت Enable نیز always enable را
انتخاب میکنیم.
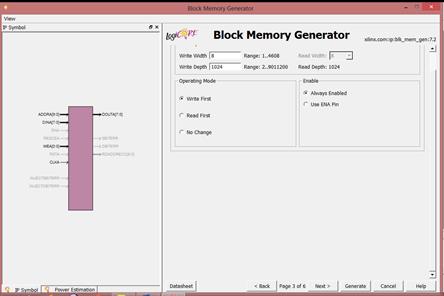
در مرحله بعد، قسمتOptional output Register
مشخص میکند خروجی که از حافظه میگیریم یک طبقه رجیستر شود یا خیر.
معایب رجیستر کردن: تعدادی فلیپ فلاپ مصرف میشود و یک فاز تاخیر بیشتر
داریم.
حسن رجیستر کردن:
(Pipelining) باعث میشود که تاخیر خارج شدن داده از حافظه، از تاخیرهای بعدی
جداشود.
Memory Initialization: میتوان
به حافظه مقدار اولیه داد. اگر تیک Load init file را فعال
کنیم، میتوانیم
محتویات خانههای حافظه را از یک فایل متنی با پسوند.COE بگیریم.
در قسمت fill remaining
memory locations نیز میتوان
بقیه خانههای حافظه که در فایل متنی مقدار دهی نشدهاند را مقداردهی کرد. تیکها
را فعال نمیکنیم تا مقدار اولیه به صورت پیش فرض، صفر درنظر گرفته شود.
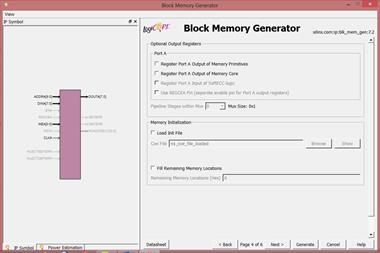
در این مرحله مشخص میکنیم که پایه reset داشته
باشیم یا خیر. معمولا reset برای حافظهها استفاده نمیشود. با فعال کردن reset، باید
نوع آن: سنکرون یا آسنکرون بودن را تعیین کرد. در اینجا reset را فعال نمیکنیم.
مرحله بعد گزینههایی برای شبیهسازی دارد. در هنگام ایجاد هر core یک functional model
نیز برای آن ایجاد میشود. در اینجا میتوان مشخص کرد که functional model روی چه چیزهایی warning
دهد. وقتی All فعال باشد زمان شبیهسازی بیشتر میشود ولی برای طرحهای کوچک این
زمان بسیار ناچیز است.

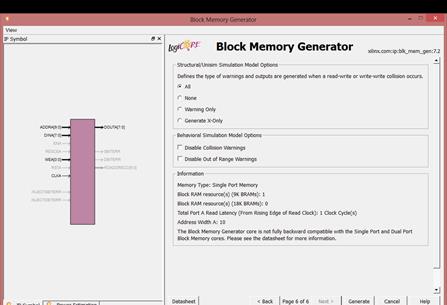
قسمت Information نیز گزارشی از ram که قرار است ایجاد شود را به ما میدهد. همان طور که در شکل
مشاهده میشود ما دو نوع block ram داریم: 9k و 18k. Read Latency مدت زمان
ظاهرشدن داده، بعد از قراردادن آدرس آن را مشخص میکند که در اینجا در یک سیکل این
کار انجام میشود. Address Width
نیز نشان دهنده این است که خطوط آدرس 10 بیتی هستند.
حال
core را
Generate میکنیم.
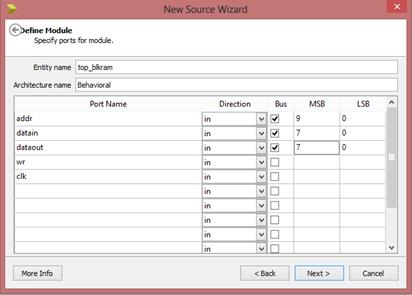
اکنون باید یک فایل top_blkram
بسازیم و blkram را در آن port map کنیم.
New -> new source -> VHDL Module
پورتهای ورودی و خروجی را مانند شکل زیر مینویسیم و next میزنیم.
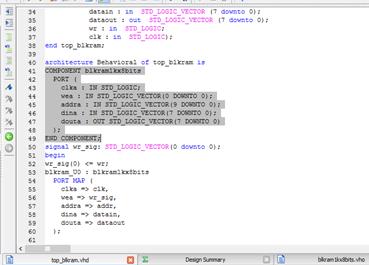
حال باید blkram را در فایل top، port map کنیم. قسمتهای
مشخص شده در شکل زیر را به فایل top
اضافه میکنیم. به این صورت که بر روی blkram کلیک کرده، فایل view HDL Instantiation tempرا انتخاب کرده و محتویات آن را copy میکنیم.
در این مرحله پورتها نیز اصلاح میشوند. باید به تفاوت نوع پایههای write(wr) و write enable(wea)
توجه داشته باشیم. wr از نوع STD_LOGIC و wea از نوعSTD_LOGIC_VECTOR
است. در نتیجه یک سیگنال برداری را تعریف میکنیم.(سیگنال
wr_sig)
برای مقدار
دهی حتما باید index سیگنال گذاشته شود. فایل را save میکنیم.



شبیهسازی حافظه:
حال باید یک فایل testbench بسازیم و نام آن را TB_top_blkram انتخاب میکنیم.
خط زیر را به فایل TB اضافه میکنیم تا آدرس را برابر با صفر قرار دهیم.

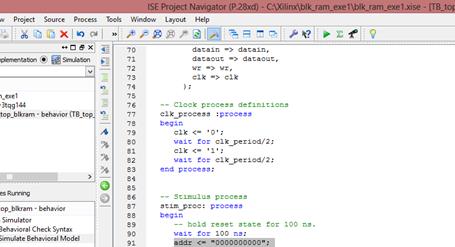
فایل را ذخیره کرده و simulation را انجام میدهیم. نتیجه شبیهسازی در شکل صفحه بعد مشخص است:
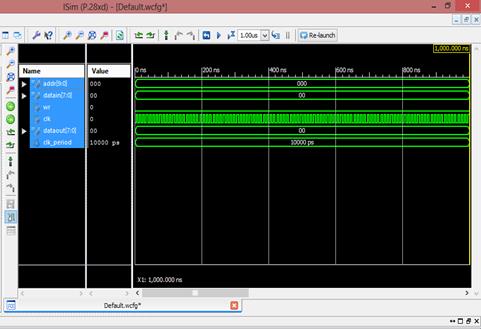
در مرحله بعد میتوانیم مقادیر را خودمان وارد کنیم. مثلا بخواهیم در
یک خانه حافظه بنویسیم و محتویات آن خانه از حافظه را بخوانیم پس باید پایههای
حافظه را مقداردهی کنیم. در
اینجا میخواهیم در خانه صفر حافظه عدد AA را write
کنیم. پایه write را 1 میکنیم و بعد از 10ns
دوباره آن را صفر میکنیم.

اگر در کد تغییراتی دادیم و
خواستیم در شبیهسازی هم اعمال شود Re_launchرا میزنیم. در این حالت شبیهساز را مجددا run کرده ایم.
نتیجه شبیهسازی:

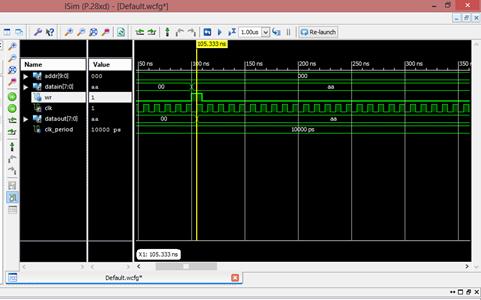
در مثالی دیگر بعد از اینکه wr را
صفر کردیم، آدرس را عوض میکنیم. به اندازه 100ns، wait انجام میدهیم و سپس مجددا آدرس را به خانه صفر برمیگردانیم.

دوباره re_launch میکنیم:
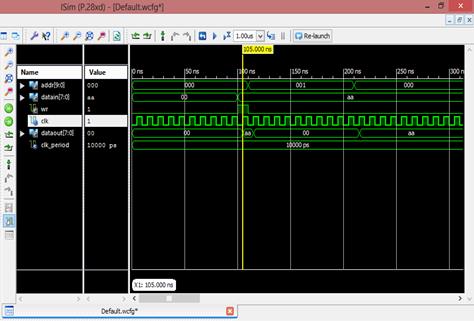
ابتدا عمل write انجام میشود.سپس از خانه صفر حافظه عمل خواندن صورت میگیرد و 100ns بعد از خانه یک حافظه عمل خواندن انجام میشود. داده در لبه
بالارونده روی باس قرار میگیرد. نتایج شبیهسازی در شکل بالا مشخص است.
13-یک حافظه BlockRAM با اندازه 512x8 ایجاد کنید. سپس یک برنامه VHDL با نام mem1024x16
ایجاد کنید و با Port Map کردن چهار عدد از حافظه بلاک رم ایجاد شده، یک حافظه 1024x16 ایجاد کنید و آن را شبیهسازی کنید(در شبیهسازی در 2 آدرس حافظه
بنویسید و سپس از همان 2 آدرس بخوانید، آدرسها را به گونه ای انتخاب کنید که در هر
یک از چهار حافظه عملیات خواندن و نوشتن انجام شده باشد)
14-با استفاده از دیتاشیت بلاک رم، فرمت
فایلهای coe را
مطالعه کنید سپس یک فایل coe ایجاد کنید و برای یک حافظه با مشخصه 8x40 یک
فایل coe
ایجاد کنید(محتویات آدرس صفر حافظه را شماره دانشجویی خود قرار دهید و برای آدرسهای
بعدی به ترتیب یک واحد به شماره دانشجویی خود اضافه کنید) سپس یک حافظه BlockRAM با
اندازه 8x40 ایجاد کنید و آن را با فایل coe ایجاد شده،
مقداردهی اولیه کنید. سپس یک TestBench بنویسید که با خواندن محتویات حافظه، از صحت مقادیر اولیه اطمینان
حاصل کنید.
15-با استفاده از نرم افزار ISE و ایجاد
انواع Coreهای حافظه از نوع distributed، و
سنتز و ایمپلیمنت آن، رابطه ای بین تعداد بیتهای حافظه از این نوع و تعداد LUTهای مصرفی بدست آورید. (راهنمایی: یک حافظه 64x16 ایجاد کنید سپس یک فایل top برای آن بنویسید و آنرا ایمپلیمنت
کنید و با باز کردن فایل با پسوند par، تعداد LUTهای مصرف شده را استخراج
کنید سپس این کار را برای چند حافظه با اندازههای دیگر تکرار کنید و رابطه را
بدست آورید)
6-1 پیش آگاهی
هدف از این آزمایش، آشنایی با FIFO و نحوه تولید آنها
توسط نرم افزار ISE میباشد و زمانبندی خواندن و نوشتن در آن و شبیهسازی
آن میباشد.
FIFO، سخت افزاری است که برای ذخیره و بازیابی دادهها به صورت صف مورد
استفاده قرار میگیرد. پیادهسازی آن به صورت BlockRAM دو پورته
است. در FIFO با هر بار خواندن شمارندهی آدرس خواندن جلو میرود و با هر بار نوشتن
آدرس یک واحد زیاد میشود.
برای پیادهسازی FIFO از BlockRAM یا حافظهی Distributed استفاده میشود. در سختافزار FIFO شرط پربودن و خالی بودن آن وجود دارد که میتوان آنها را با رجیسترها
تعیین کرد.
1-
صف: بافر کردن دادهها به صورت موقت؛ مثلاً اگر جایی سرعت
پردازش اطلاعات با سرعت ورودی یا خروجی اطلاعات یکی نیست، میتوان از این امکان FIFO
استفاده کرد. یا در بحث شبکه، وقتی بستههای دریافتی کامل شد آنها را برای پردازش
بفرستد. و برای این مورد اگر در FIFO بنویسیم بهتر از حافظه است چون نیازی نیست آدرس آن را خودمان
تولید کنیم.
2-
کاربرد مهمتر این است که وقتی در مدار دو کلاک داشته
باشیم و بخواهیم بین این دو قسمت از برنامه داده جابهجا کنیم، بین آنها یک FIFO
قرار میدهیم و قسمت اول با کلاک خودش در FIFO مینویسد و دومیبا کلاک خودش از FIFO
میخواند، بنابراین مشکل عدم پایداری به وجود نمیآید.
مورد دیگر: در پردازش اطلاعات شبکه کلاک پردازش شبکه و کلاک پردازش
داخلی متفاوت است، برای حل این مشکل هم از FIFOاستفاده
میکنیم.
ابتدا پروژه جدیدی ایجاد میکنیم و سپس راست کلیک روی پروژهی ساخته
شده و New Source را انتخاب میکنیم و گزینهی
) IP(CORE Generator & Architecture Wizard را انتخاب میکنیم. در اینجا میخواهیم یک FIFO
با اندازه ی 16K که هر کلمهی
آن 8 bit است
بسازیم.
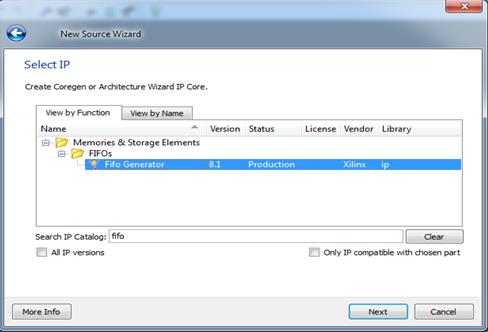
پس از آن در قسمت search عبارت FIFO را جستجو
میکنیم و Fifo Generator را انتخاب کرده و Next را انتخاب میکنیم.
کمترین تعداد پورتهای Fifo
، 6 تا است که در شکل نشان داده شده
اگر RST را حذف کنیم بقیه پورتها 6 تا هستند. ( به غیر از clock
). در این مرحله Native را انتخاب کرده و سپس Next.
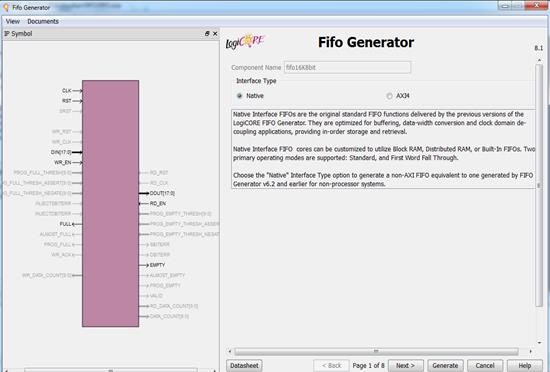
در این قسمت گزینههای مختلفی میبینید که چهار گزینهی اول مربوط به
ساختن Fifo با یک کلاک
هستند که Synchronous Fifo است. و سه گزینهی بعد مربوط به ساختن Fifo با دو کلاک است که ASynchronous
Fifo است.
همچنین در اینجا نوع حافظهای که میخواهید Fifo با آن
ساخته شود را انتخاب میکنید. برای مثال ساختن با
Shift register ، Block RAM ،Distributed RAM.
-
Built-in-FIFO، Fifoی است که خودش پیادهسازی
شده و مدارها را دارد.
بر اساس محدودیت سخت افزاری که داریم، اینکه FIFO با چه
ساخته میشود را انتخاب میکنیم. مثلا اگر BlockRAMها را میخواهیم در جای دیگر استفاده کنیم، در اینجا این گزینه را
انتخاب نمیکنیم. به طور کلی همهی اینها از نظر سرعت یکسانند، بسته به مدار یکی
را انتخاب میکنیم. که در اینجا همان گزینهی اول را انتخاب کنید و سپس Next.
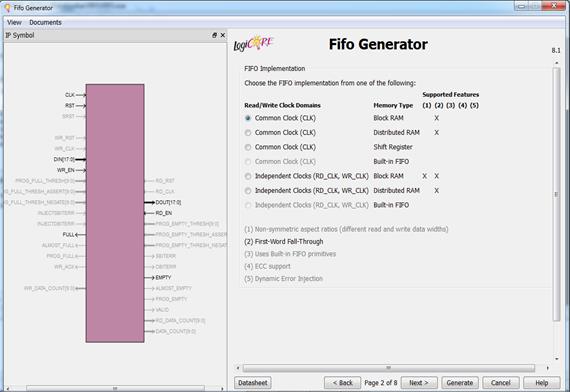
در این قسمت ابتدا نوع خواندن (Read Mode) را انتخاب میکنیم.
-
Standard
FIFO: با انتخاب این گزینه تا زمانی که
سیگنال Read
را فعال نکنیم داده روی خروجی نمیآید و وقتی سیگنال Read را فعال کردیم، یک پالس بعد داده روی خروجی میآید.
-
First-Word
Fall- Through: با انتخاب این گزینه اولین
داده به محض انجام شدن Write روی خروجی میآید و نیازی به فعال کردن سیگنال Read
برای آن نیست ولی دادههای بعدی مانند گزینهی اول، پس از فعال شدن سیگنال Read روی خروجی ظاهر میشوند.
در اینجا ما گزینهی اول را انتخاب میکنیم چون فرقی بین کلمهها نمیگذارد!
Built-in FIFO
Options:
اگر در قسمت کلاک، کلاکها را متفاوت در نظر میگرفتیم در این قسمت
باید اندازهی آنها را مشخص میکردیم.
Data Port
Parameters:
در این قسمت طول کلمه و تعداد کلمات را برای Fifo انتخاب میکنیم.
و سپس Next.
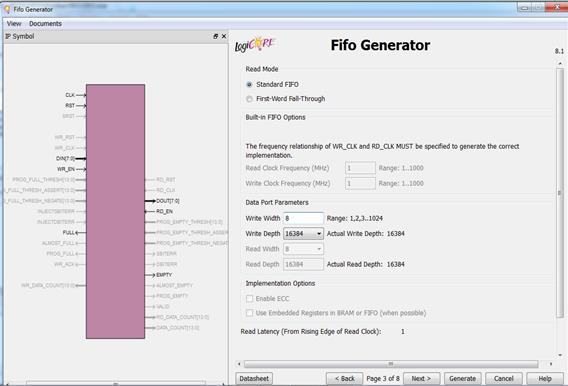
کاربرد Flagهای مختلف:
-
Write
Acknowledge Flag:
اگر قبل از انجام عمل write
، پر بودن Fifo را چک
کردیم نیازی به این Flag نیست. اما اگر اینکار را انجام ندادیم، با چک
کردن این Flag متوجه میشویم که عمل نوشتن به درستی انجام شده
است یا خیر. چون ممکن است Fifo پر بوده باشد و ما عمل نوشتن را انجام دهیم و نوشتن انجام نگیرد.
-
Overflow
Flag:
وقتی Fifoپر باشد و ما عمل
نوشتن را انجام دهیم این پرچم فعال میشود.
-
Valid
Flag:
وقتی داده روی پورت قرار گرفت، یک کلاک بعد این Flag فعال میشود
و با فعال شدن آن میتوانیم داده را بخوانیم.
-
Underflow Flag:
وقتی Fifo خالی بوده و ما عمل خواندن انجام دادیم، این Flag
فعال میشود.
در این مرحله میتوانیم هر کدام از پرچمهایی که میخواهیم را فعال
کرده و سپسNext.
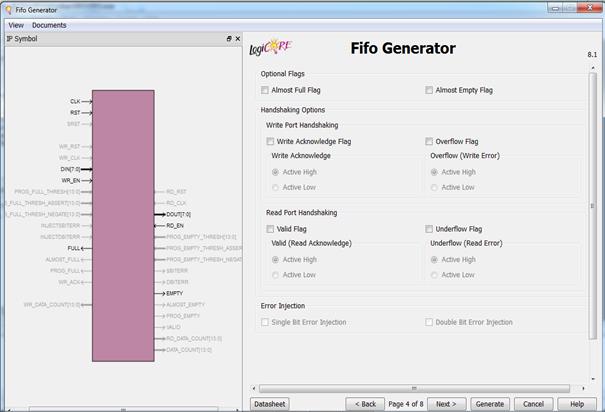
در این مرحله میتوانیم انتخاب کنیم که میخواهیم Reset Pin
داشته باشیم یا نه و Reset ما به صورت Synchronous باشد یا Asynchronous.
-
Full
Flags Reset Value: اگر مقدار یک را انتخاب
کنیم، یعنی وقتی Reset فعال شد، Full یک میشود
و اجازه ی نوشتن داده نمیشود و در واقع کسی که داده مینوشته دیگر نمینویسد. و
در قسمت پایین آن انتخاب میکنیم که وقتی Reset فعال شود، چه
مقداری روی خروجی نشان داده شود.
-
Programmable
Full Type: وقتی میخواهیم فعال شدن full
زودتر به ما اطلاع داده شود. و در واقع تعداد کلمات به حدی که میخواهیم رسید full
فعال شود.
-
Full
Threshold Assert Value: مقداری که
در این قسمت تعیین میکنیم، وقتی تعداد کلمات به این مقدار رسید به ما هشدار میدهد.
-
Full
Threshold Negate Value: وقتی
تعداد کلمات به این مقدار برسد، full فعال میشود.
همچنین با انتخاب گزینهی Single
Programmable Full Threshold Input Port
از قسمت Programmable Full Type میتوانیم، از طریق دادن ورودی میتوانیم این
محدوده را مشخص کنیم و از این طریق میتوان به صورت پویا محدوده را عوض کرد.
در مورد Empty هم به همین صورت است. مثلا تعیین میکنیم اگر دو
کلمه نوشته شد، Empty غیر فعال شود.
کاربرد Data Count به این صورت است که با دانستن ظرفیت و مقدار Data Count میتوانیم بفهمیم چقدر از Fifo پر شده است. در این قسمت همچنین میتوانیم تعیین کنیم طول Data Count چقدر باشد. برای مثال اگر طول داده در Fifo با 14 رسید
یکی بشمارد.
اگر در مرحلهی اول گزینهی AXIS را به جای Native انتخاب میکردیم تنظیمات این مرحله قابل تغییر بود.
در مرحله ی آخر یک سری اطلاعات از Fifo که قرار
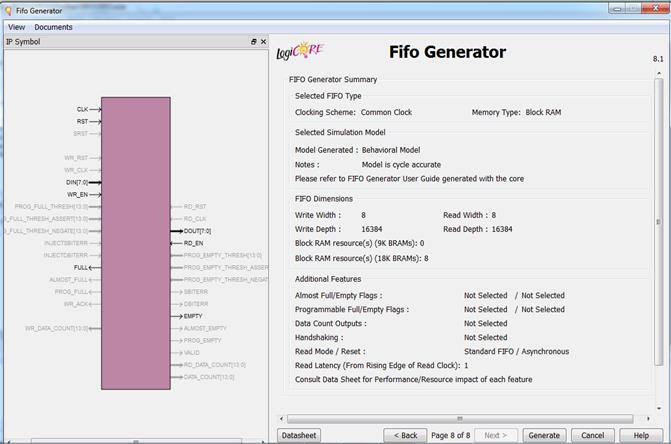
است ساخته شود به ما میدهد. در این مرحله Generate را انتخاب میکنیم و Fifo با تنظیمات انتخاب شده توسط ما ساخته میشود.
پس از ساخته شدن Fifo یک فایل FIFO_TOP برای آن، با
مشخصات زیر میسازیم.
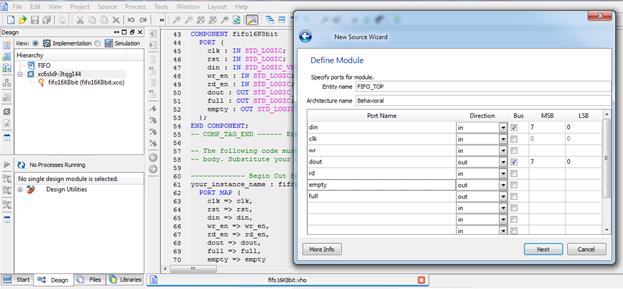
با انتخاب فایل Fifo ساخته شده و باز کردن فایل View HDL Instantation Template میتوانید قطعه کد Component و Port Map را در فایل FIFO_TOP کوپی کنید.
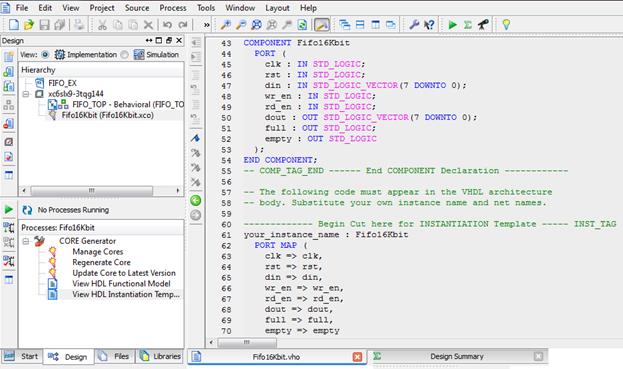
شکل زیر تغییرات انجام شده پس از کپی کردن PortMap و Component در فایل FIFO_TOP را هم نشان میدهد.
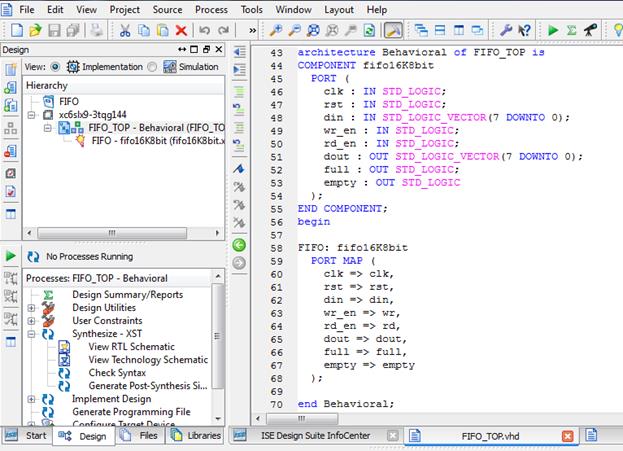
پس از آن از فایل TOP یک فایل TestBench میسازیم. با دادن مقادیر زیر میتوانیم هر یک از دستورات Reset،
Write
و Read را امتحان کنیم.
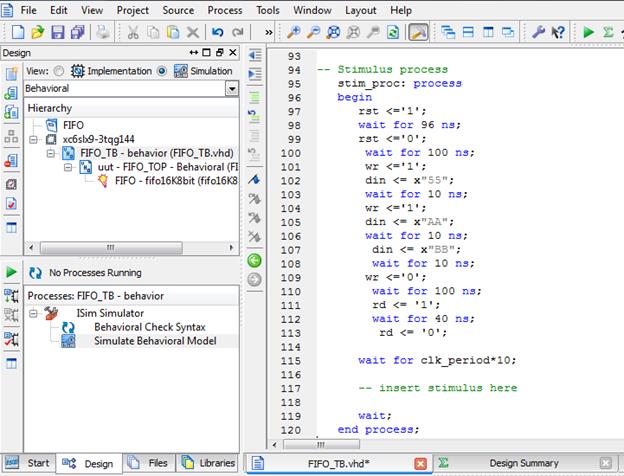
در شبیهسازی که طبق مقادیر داده شده در شکل قبل انجام میشود، مشاهده میکنید
که هم زمان با فعال شدن Reset،Full هم فعال شده و تا 3 کلاک پس از غیر فعال شدن Reset هم فعال باقی مانده است. و این نشان دهندهی این است که بلافاصه بعد از
Reset کردن نمیتوانیم در Fifo عمل نوشتن را انجام دهیم.
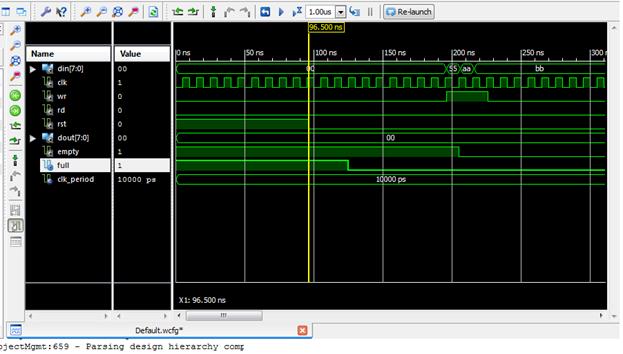
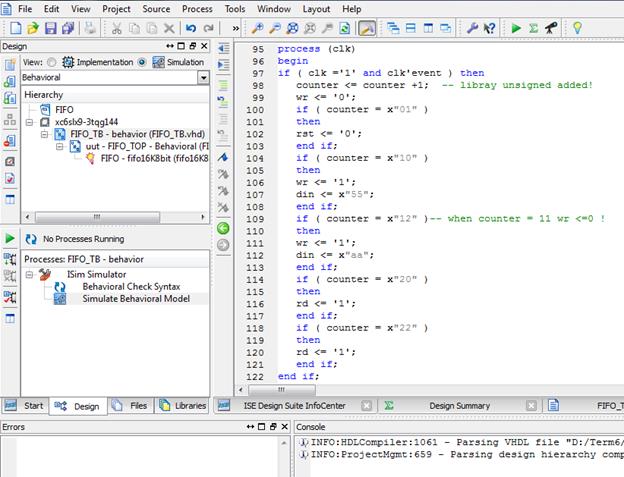
در فایل TestBench اگر لیست حساسیت در Process بنویسیم، دیگر نیازی به نوشتن Wait نیست و مدار Syncron با کلاک عمل میکند و مشکلی به وجود نمیآید.
مانند شکل زیر اگر در فایل Test Bench لیست
حساسیت بنویسیم دیگر نیازی به استفاده از wait نیست. توجه شود که
در شکل زیر از counter برای شمردن استفاده شده است. روش دیگر برای
نوشتن لیست حساسیت استفاده از state
Machine است که counter خود یک state Machine است. توجه کنید در اینجا چون از عملگر + استفاده شده باید USE ieee.std_logic_unsigned.ALLبه عنوان کتابخانه
اضافه شود. در این قسمت مقدار wr صفر داده شده و در زمآنهایی که میخواهیم فقط
مقدارش یک میشود. در مورد rd این طور نیست و وقتی که مقدارش را یک کنیم تا وقتی که دوباره با
شرط آن را تغییر نداده ایم، یک باقی میماند.
در شبیهسازی میتوانید متوجه این موضوع شوید.
1-
برنامهای بنویسید که مدار شکل روبرو را پیادهسازی کند.
ساختار داخلی این مدار به این صورت است که یک فیفو با عمق 128 و عرض 16 بیت است که
امکان نوشتن دیتا از بیرون را دارد و هر وقت لبه بالارونده روی سیگنال Start
مشاهده شد، خواندن از فیفو شروع میشود و تا موقعی که فیفو خالی شود مقادیر داخل
آن را با همدیگر جمع میزند.

برای مدار فوق یک TestBench
بنویسید که مقادیر 1 تا 10 را در فیفو بنویسد سپس یک لبه بالارونده روی Start
ایجاد کند.
2-
برنامهای بنویسید که مدار شکل روبرو را پیادهسازی کند.
در این مدار از دو بلاک رم از نوع Simple Dual Port با
اندازه 128x8 استفاده شده است. پورت A از بلاک رم
BRAM1 از
بیرون قابل دسترس است و میتوان در آن عمل نوشتن را انجام داد. عملکرد مدار به این
گونه باشد که با دیدن لیه بالا رونده روی پورت Copy، محتویات
آدرسهای 0 تا 10 بلاک رم 1 خوانده شده و با عدد 55 جمع زده میشود و در بلاک رم 2
نوشته میشود. با دیدن لیه پایین رونده روی پورت Show، محتویات
آدرسهای 0 تا 10 از بلاک رم2 خوانده شده و روی پورت Dout گذاشته میشود.
برای مدار فوق یک TestBench
بنویسید که مقادیر 100 تا 110 را در آدرسهای صفر تا 10 بلاک رم 1 بنویسد و سپس یک
لبه بالارونده روی Copy ایجاد کند و نهایتا یک لیه پایین رونده روی سیگنال Show ایجاد کند.

7 آزمایش هفتم:
آشنایی با ردههای مختلف شبیهسازی:
فانکشنال و Post Route Simulation
7-1 پیش آگاهی
هدف از این آزمایش، آشنایی با ردههای مختلف شبیهسازی با استفاده از
نرم افزار ISE میباشد.
برای اینکه از صحت عملکرد یک برنامه VHDL اطمینان
حاصل شود باید آن را در مراحل مختلف شبیهسازی کرد. علت این امر را با یک مثال
روشن میکنیم. ممکن است شما برنامه VHDL خود را شبیهسازی کنید و خروجیهای مدار دقیقا همان نتایج مورد انتظار
شما باشد ولی وقتی که برنامه سنتز میشود، قسمتهایی از برنامه حذف گردند (مثلا از
دستورات تاخیر در برنامه استفاده کرده باشید که قابل سنتز نیستند) بنابراین وقتی
که مدار خود را روی FPGA پیادهسازی میکنید، نتیجه مورد انتظار تولید
نخواهد شد. برای اینکه مشکلاتی از قبیل فوق رخ ندهد و شما بتوانید از صحت عملکرد
مدار خود بعد از انجام مراحل سنتز، MAP و Place and Route
اطمینان حاصل کنید، در نرم افزار ISE این قابلیت فراهم شده است تا برنامه خودر را در ردههای زیر شبیهسازی
کنید:
الف) شبیهسازی فانکشنال یا رفتاری (Behavioral simulation)
ب) شبیهسازی بعد از مرحله Translate (Post Translate simulation)
ج) شبیهسازی بعد از انجام مرحله MAP (Post MAP simulation)
د) شبیهسازی بعد از مرحله Place and Route (Post Route simulation)
در ادامه با ذکر یک مثال، روش انجام شبیهسازی در ردههای مختلف بیان میشود.
ابتدا به عنوان نمونه یک جمع کننده 8 بیتی ایجاد کرده و سپس تست بنچ
مربوط به آن را مینویسیم.
نمونه کد یک جمع کننده 8 بیتی در زیر مشاهده میشود. دقت کنید که
کتابخانه unsigned نیز در پروژه استفاده شده است.

حال نوبت به نوشتن تست
بنچ مربوطه است.
اگر نوع شبیهسازی را از نوع Behavioral انتخاب کنیم نتیجه شبیهسازی
بدون در نظر گرفتن تأخیرهای سخت افزاری به ما نشان داده میشود. (فقط رفتار کد ما
شبیهسازی میشود ) و اگر Post-Translate انتخاب کنیم شبیهسازی کد Translate شده انجام میشود و
همینطور اگر Post – Route را انتخاب کنیم مدار Route شده شبیهسازی میشود. )
نمونه شبیهسازی شده (
مرحله Behavioral) را در شکل زیر مشاهده میکنید.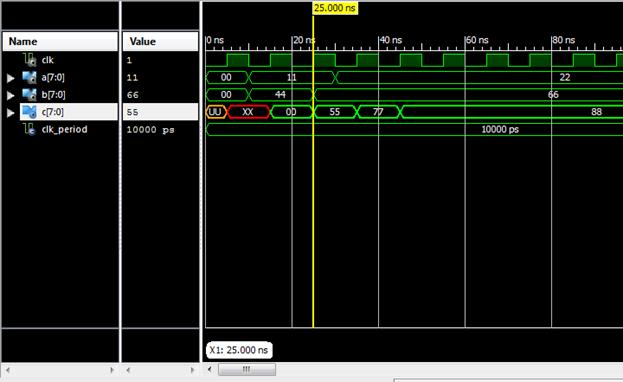
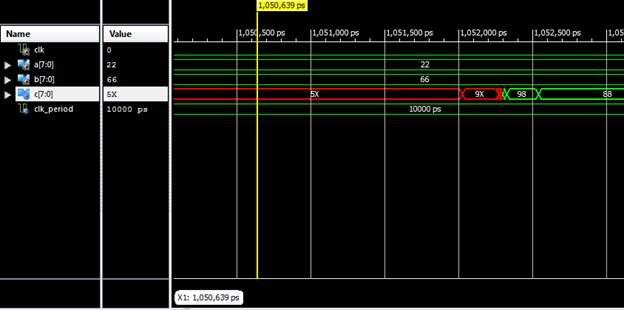
نمونه شبیهسازی شده (
مرحله Post – Route ) را در شکل زیر مشاهده میکنید. ( دلیل قرمز بودن برخی سیگنالها
تأخیرهای سخت افزاری پیادهسازی کد بر روی تراشه میباشد )
1-

با استفاده از
ماشین حالت، برنامهای بنویسید که مدار شکل روبرو را پیادهسازی کند. عملکرد این
مدار به این صورت است که رشته ای از بیتها را به صورت سریال دریافت میکند و تعداد
دفعات تکرار رشته 110010 را شمارش میکند. با فعال شدن سیگنال Rst، مقدار
شمارنده خروجی، صفر خواهد شد. رشته ورودی به صورت سریال از پورت Serial_In
وارد میشود و سیگنال Valid، معتبر بودن بیت موجود روی پورت Serial_In را مشخص میکند.(توجه
کنید که رشته بیتهای وارد شده به ماجول از کم ارزش به پر ارزش است)
2- شبیهسازی
فانکشنال یا رفتاری (Behavioral
simulation) را برای مدار فوق انجام دهید و
نتایج را به مسئول آزمایشگاه نشان دهید.
3- شبیهسازی
بعد از مرحله Translate (Post Translate simulation) را برای
مدار فوق انجام دهید و نتایج را به مسئول آزمایشگاه نشان دهید.
4- شبیهسازی
بعد از انجام مرحله MAP (Post MAP simulation) را برای
مدار فوق انجام دهید و نتایج را به مسئول آزمایشگاه نشان دهید.
5- شبیهسازی
بعد از مرحله Place and Route (Post Route simulation) را برای
مدار فوق انجام دهید و نتایج را به مسئول آزمایشگاه نشان دهید.
از برنامه زیر به عنوان TestBench استفاده کنید:
بعد از شبیهسازی اولیه، برنامه TestBench را به گونه
ای تغییر دهید که شماره دانشجویی شما به صورت باینری وارد ماجول Pattern_count
شود و الگوی 110010 در آن جستجو گردد.
LIBRARY
ieee;
USE
ieee.std_logic_1164.ALL;
USE
ieee.math_real.ALL; -- for UNIFORM, TRUNC functions
USE
ieee.numeric_std.ALL; -- for TO_UNSIGNED function
ENTITY
TB_Pattern_Count IS
END
TB_Pattern_Count;
ARCHITECTURE
behavior OF TB_Pattern_Count IS
COMPONENT
pattern_count
PORT(
Clk
: IN std_logic;
Rst
: IN std_logic;
valid
: IN std_logic;
Serial_in
: IN std_logic;
Count
: OUT std_logic_vector(7 downto 0)
);
END
COMPONENT;
--Inputs
signal
Clk : std_logic := '0';
signal
Rst : std_logic := '0';
signal
valid : std_logic := '0';
signal
Serial_in : std_logic := '0';
--Outputs
signal
Count : std_logic_vector(7 downto 0);
--
Clock period definitions
constant
Clk_period : time := 10 ns;
signal
pattern:std_logic_vector(31 downto
0):="11001011011011001011001001001011";
type
s_type is(idle,working,random_wait,finish);
signal
tb_state :s_type:=idle;
signal
wait_counter: integer range 0 to 7:=0; -- Random integer value in range 0..7
signal
Serial_counter: integer range 0 to 255:=0;
BEGIN
--
Instantiate the Unit Under Test (UUT)
uut:
pattern_count PORT MAP (
Clk
=> Clk,
Rst
=> Rst,
valid
=> valid,
Serial_in
=> Serial_in,
Count
=> Count
);
--
Clock process definitions
Clk_process
:process
begin
Clk
<= '0';
wait
for Clk_period/2;
Clk
<= '1';
wait
for Clk_period/2;
end
process;
process(clk)
variable
rand: real; -- Random real-number value in range 0 to 1.0
variable
seed1, seed2: positive; -- Seed values for random generator
begin
if(clk='1'
and clk'event)then
valid
<='0';
Rst
<='0';
case
tb_state is
when
idle =>
Rst
<='1';
tb_state
<= working;
when
working =>
Serial_in
<= pattern(0);
Serial_counter
<=Serial_counter+1;
pattern
<= '0' & pattern(31 downto 1);
valid
<='1';
UNIFORM(seed1,
seed2, rand) ;
wait_counter<=
INTEGER(TRUNC(rand*5.0));
if(Serial_counter=32)then
tb_state
<= finish;
else
tb_state
<= random_wait;
end
if;
when
random_wait =>
wait_counter
<= wait_counter-1;
if(wait_counter=0)then
tb_state
<= working;
end
if;
when
finish =>
null;
when
others =>
tb_state
<= working;
end
case;
end
if;
end
process;
--
Stimulus process
stim_proc:
process
begin
--
hold reset state for 100 ns.
wait
for 100 ns;
wait
for Clk_period*10;
--
insert stimulus here
wait;
end
process;
END;
8-1 پیش آگاهی
هدف این آزمایش آشنایی با نرمافزار ChipScope میباشد. این نرمافزار جزو قابلیتهای ISE میباشد که این امکان را فراهم میکند که بتوان سیگنالهای داخلFPGA را مانند اسیلوسکوپ نمونه برداری کنیم و توسط
کابل JTAG در کامپیوتر نشان دهیم.
استفاده از نرمافزار ChipScope را با یک مثال برای یک شمارنده پی میگیریم:
بعد از پیادهسازی شمارنده،برای استفاده از نرمافزار
ChipScope از
قسمت New Source گزینه ChipScope Definition and Connection
File را انتخاب میکنیم. سپس یک اسم انتخاب میکنیم.
بعد از انجام این کار یک فایل با پسوند cdc به پروژه اضافه
میشود. بر روی آن کلیک میکنیم تا تنظیمات لازم را انجام دهیم. در قسمت اول و دوم
Next را میزنیم. سپس به قسمتی میرسیم که در آن مشخص میکنیم که چه سیگنالهایی
نشان داده شود.
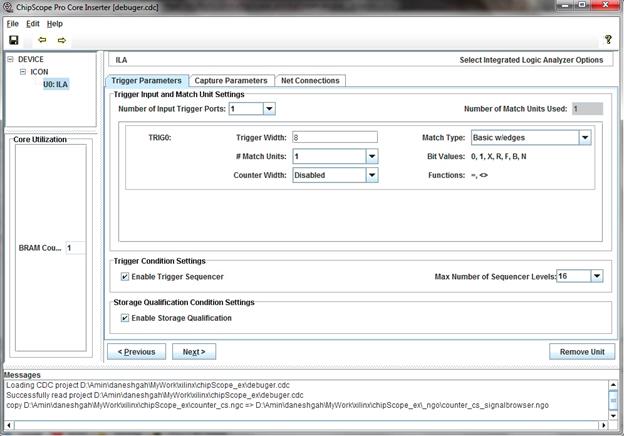
بررسی سیگنالها به صورت آنلاین نمیباشد، بلکه به صورت تریگر میباشد.
به این صورت که سیگنال مورد نظر را به عنوان تریگر معرفی کرده، و سپس در نرمافزار
ChipeScope مشخص میکنیم که در چه صورتی مقدار آن نمونه برداری شود. سیگنال تریگر
میتواند به صورت تک بیت یا به صورت باس باشد. در این قسمت سیگنالهای تریگر را مشخص میکنیم.
در این مثال میخواهیم دو سیگنال ریست و هشت بیت از بیتهای شمارند را به
عنوان تریگر داشته باشیم. برای این کار ابتدا عدد دو را در قسمت
Trigger Input
and Match Unit Settings انتخاب میکنیم، سپس
تعداد بیتهای سیگنالهای تریگر را در قسمت Trigger Width مشخص میکنیم. سپس به قسمت بعدی میرویم.
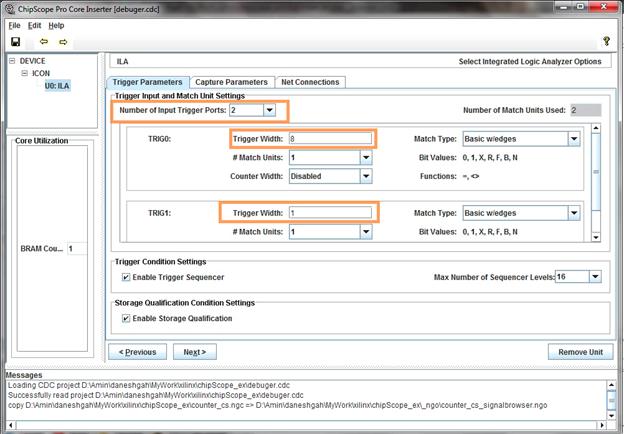
در این مرحله تعداد نمونهها را مشخص میکنیم. به این معنی که مشخص میکنیم
که هرگاه شرط مورد نظر برقرار شد، چند تا نمونه برداشته شود. تعداد نمونهها را در
قسمتData Depth مشخص میکنیم. در این مثال عدد 1024 را انتخاب میکنیم. سپس به قسمت بعدی میرویم.
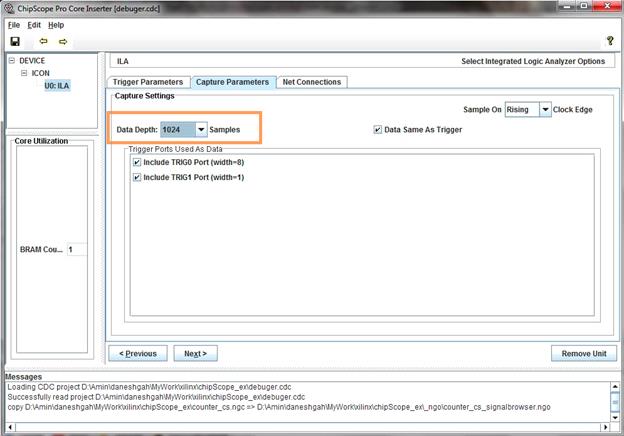
در این قسمت، تریگرها را به سیگنالهای داخلی وصل میکنیم. برای این کار
گزینه Modify Connections را انتخاب میکنیم.
سپس در قسمت Clock
Signals مشخص میکنیم که بر اساس چه کلاکهایی نمونهها برداشته شود. برای انتخاب
سیگنالهای کلاک،سیگنالهای مورد نظر را
از لیست سیگنالهای داخلی FPGA که در قستمت سمت چپ قابل مشاهده هستند، انتخاب و
سپس Make Connection را انتخاب میکنیم.
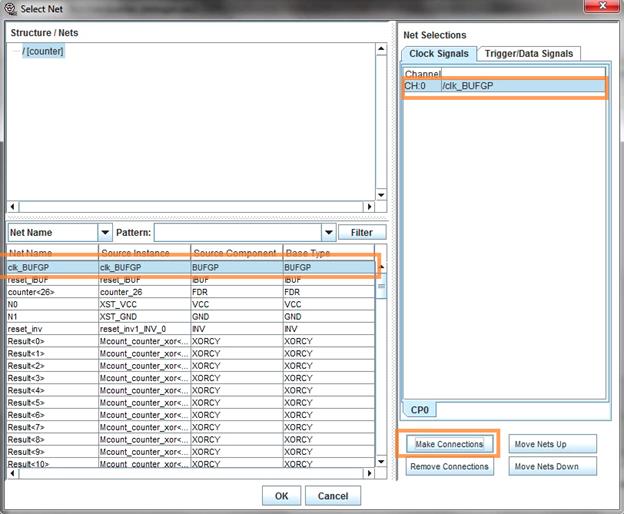
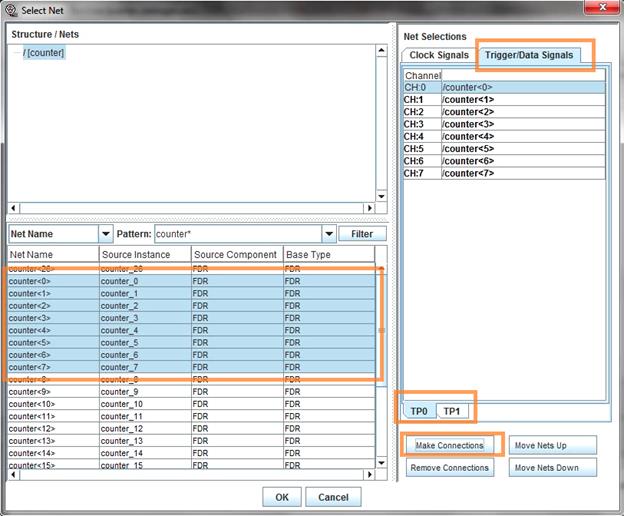
برای وصل کردن سیگنالهای تریگر قسمت Trigger/Data Signals را انتخاب میکنیم. سپس سیگنالهای داخلی FPGA را مانند قبل متصل میکنیم. برای وصل
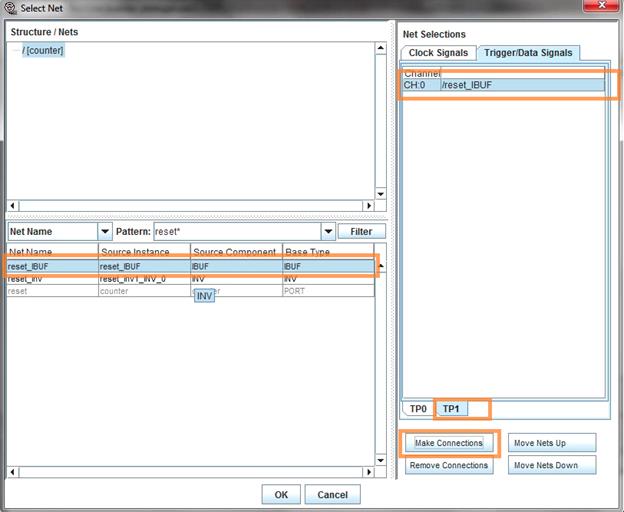
کردن سیگنال تریگر دوم از قسمت پایین TP1 را انتخاب میکنیم. سپس مانند قبل عمل میکنیم.
سپس OK را انتخاب میکنیم.
در قسمت جدید گزینه Return
to Project Navigator را انتخاب میکنیم.
بعد از آن
باید پروژه را سنتز و ایمپلیمنت کنیم.
بعد از آن گزینه Analyze
Design Using ChipScope که جدید اضافه میشود
را انتخاب میکنیم.
سپس نرمافزار ChipeScope باز
میشود. از
همین برنامه میتوان برای پروگرم کردن
FPGA نیز استفاده کرد. برای این کار کابل JTAG را وصل میکنیم و سپس JTAG Chain را میزنیم
و گزینه okانتخاب میکنیم. بعد از آن در قسمت بالای صفحه به منو Device میرویم و FPGA مورد نظر را انتخاب و بعد از آن گزینهConfigure را انتخاب میکنیم. در نهایت گزینه okانتخاب میکنیم تا FPGA پروگرم شود.

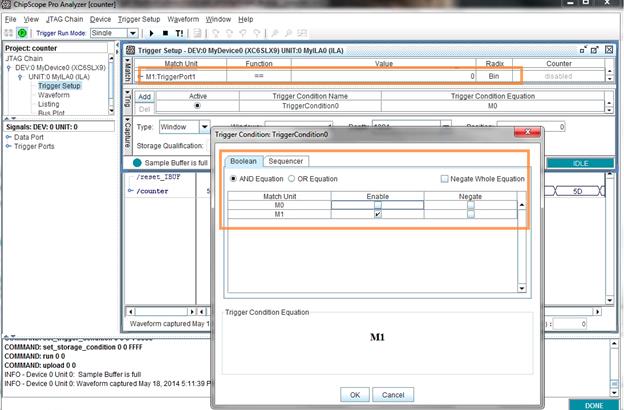
بعد از آن بر روی Waveform و Trigger Setup دابل کلیک میکنیم تا به قسمت سمت راست اضافه شوند. در قسمت Trigger Setup میتوان تریگر را تعریف کرد. در این مثال تریگر را یک شدن رقم اول شمارند
در نظر میگیریم. برای این کار رقم اول value سیگنال اول را از X به یک تغییر میدهیم. سپس
گزنیه PLAY را از بالای صفحه انتخاب میکنیم. در قسمت Waveform
نمونهها قابل مشاهده هستند.
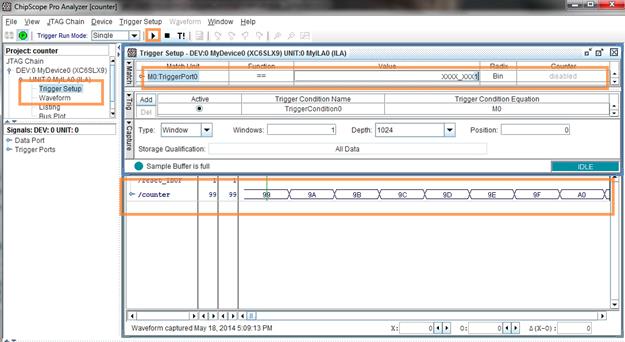
برای اضافه کردن تریگر دوم بر روی M0 کلیک کرده و
در منو جدید مشخص میکنیم که شرط تریگر کدام سیگنالها باشد. امکان and و or کردن شرطها نیز وجود دارد. بعد از آن مقدار تریگر سیگنال دوم را
در قسمت Trigger Setup مانند قبل تعیین میکنیم.
1-

در این آزمایش قصد
داریم برای ماجول UART یک TestBench تهیه کنیم سپس با استفاده از نرم افزار ChipScope سیگنالهای
درونی آن را ببینیم.
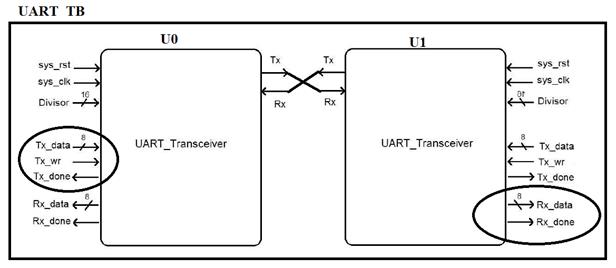
با توجه به اینکه خطوط Tx و Rx این ماجول به صورت سریال است، نوشتن تست بنچ و همچنین چک کردن
بیتهای ارسالی کاری پیچیده است. برای ساده تر شدن تست این ماجول طرحی به صورت زیر
پیشنهاد میشود که در داخل تست بنچ از دو ماجول UART استفاده
شود سپس برای تست، در یک ماجول یک بایت نوشته شود(با استفاده از خطوط Tx_wr و Tx_Data) و
منتظر بمانیم تا در ماجول دوم خط Rx_Done فعال شود. با این تست به راحتی قسمت فرستنده و گیرنده ماجول UART تست خواهد
شد. (راهنمایی: وقتی با استفاده از نرم افزار ISE، تست بنچ
را ایجاد کردید، پورت مپ شدن ماجول UART را تکرار کنید و سیگنالهای مورد نیاز را تعریف کنید و طبق شکل زیر،
پورتهای Rx و Tx را به
یکدیگر متصل کنید)
9 آزمایش نهم: آشنایی با پردازندههای امبد شده در FPGA ((MicroBlaze
9-1
پیش آگاهی
موضوع این جلسه ی آزمایشگاه در مورد پیادهسازی محیطهای Embedded
در بوردهای FPGA میباشد. به گونه ای که بتوان بستر نرم افزاری
برای برنامه نویسی سطح بالا در FPGA را فراهم کرد.
9-1-1 FPGA
در محیطهای Embedded
FPGAها با تمام قابلیتها
و ساختاری که در خود دارند، در طراحیها انعطاف پذیری کمیاز خود نشان میدهند. در
واقع نیاز به یک تغییر کوچک در یک مدار ممکن است نیاز به تغییر در کل طراحی و
ساختار برنامه ی نوشته شده داشته باشد. به همین منظور بعضی از پردازشها در بوردها
به صورت نرم افزاری انجام میشود. به عبارت دیگر میتوان قسمتهای مهم کد را در
قالب کد VHDL
(شتاب دهنده ی سخت افزاری) و سایر پردازشها را از طریق برنامه نویسی نرم افزاری
(بستر نرم افزاری) انجام داد.
برای ایجاد بستر نرم افزاری نیاز به یک پردازنده داخل FPGA
است که برنامه ی نرم افزاری را بتواند اجرا کند. ایدههای مطرح شده برای ایجاد این
پردازنده به دو صورت Soft
Processor و Hard Processor میباشد.
در ایده ی Soft
Processor هدف ایجاد یک پردازنده به کمک کد VHDL
مثل پردازنده ی مانو است. در این حالت منابع FPGA مانند LUTها و Flip Flopها مصرف خواهند شد.
یکی از این نوع پردازندهها Pico
Blaze است که طراحی آن بسیار بهینه و با
دستورات کمی ایجاد شده که منابع بسیار کمی از بورد را استفاده میکند. نوع دیگر از
این نوع پردازندهها Micro Blaze است که بعد از Pico Blaze توسط شرکت Xilinx پشتیبانی شده و اولین Soft Processor تجاری به
شمار میرود.
در حالت Hard Processor با اضافه کردن IC و مدارهای مورد نیاز یک پردازنده به FPGA، پردازنده
ی مورد نیاز برای بستر نرم افزاری ایجاد میشود که در این حالت منابع FPGA
مصرف نخواهند شد و Performance مدار نیز افزایش خواهد یافت. به عنوان مثال برای این نوع میتوان
به هسته ی پردازنده ی Cortex شرکت ARM و Power PC اشاره کرد.
EDK (Embedded
Development Kit) بخشی از نرم افزار ISE
است که در آن میتوان یک سیستم Embedded را ایجاد و آن را مدیریت نمود. فولدر EDK شامل دو
بخش XPS
(Xilinx Platform Studio) و SDK (Xilinx Software
Development Kit) است. XPS برای مشخص
کردن ساختار سخت افزاری استفاده میشود (مثلا نوع و تعداد پردازندهها، پورتها، محدوده
ی آدرسها و ...). بعد از این که این ساختار مشخص شد، XPS با ساختن
یک فایل Bit
ما را به نرم افزار SDK هدایت میکند تا در آن قسمت برنامههای مورد نیاز خود را برای
پردازش به زبان سطح بالا بنویسیم. به عبارت دیگر در نرم افزار XPS
ساختار سخت افزاری سیستم خود را مشخص و در نرم افزار SDK برای آن
ساختار، برنامه نویسی سطح بالا انجام میدهیم.
 بعد از باز کردن نرم افزار XPS
مطابق شکل زیر خواهیم
بعد از باز کردن نرم افزار XPS
مطابق شکل زیر خواهیم
داشت:
مطابق شکل اولین گزینه Base
System Builder است که به صورت پیش فرض نیز
انتخاب شده است. اصطلاحا به اجزای سخت افزاری که کنار هم گذاشته میشود، Base System
گفته میشود که در واقع سیستم پایهای است که برنامههای نوشته شده روی آن سوار
خواهد شد. با انتخاب گزینه ی Base
System، در مرحله ی بعد نام و مسیر دلخواه
خود را (اشاره به یک فولدر خالی) به فیلدهای موجود میدهیم )مسیر داده شده نباید شامل Space
باشد).
مرحله ی بعد انتخاب کردن نوع باس سیستم از دو نوع PLB
(یک نوع باس شرکت IBM) و AXI (یک نوع باس از Xilinx که برای بوردهای جدید طراحی شده) میباشد که برای راحتی کار و جهت
استفاده از بوردهای قدیمی، از نوع PLB استفاده میکنیم. باسهای مختلف در پشتیبانی کردن آدرسها، پهنای
باند، تعداد دستگاههای I/O و ... با هم متفاوت اند.
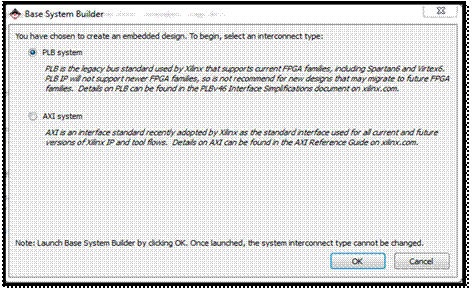
با انتخاب گزینه ی OK وارد Base System
Builder Wizard میشویم که شامل
مراحلی برای ساخت Base
System است.
اولین قدم مرحله ی Welcome است. این مرحله میتوان یک طراحی جدید ایجاد کرد یا از طراحیهای
قبلی استفاده کرد.
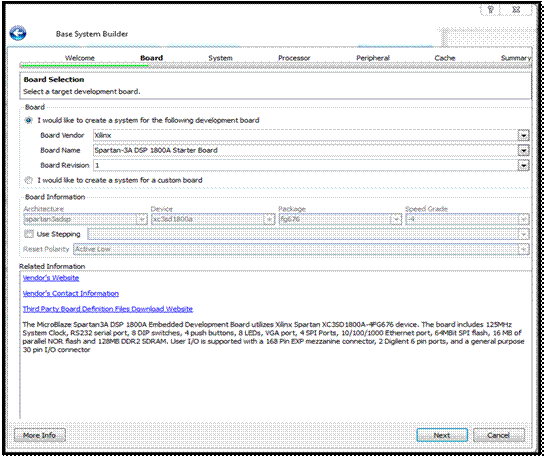
با انتخاب ایجاد یک طراحی جدید، وارد مرحله ی Board میشویم. هدف اصلی در این مرحله انتخاب بورد پایه برای ساخت Base System
است تا نرم افزار بتواند بر اساس اجزا و مشخصات آن بورد، Wizard را آماده
کرده و جزئیات بیشتری درباره ی صفات سخت افزاری سیستم از ما بخواهد (این که مثلا
از کدام یک از ویژگیهای بورد و هر کدام به چه تعداد استفاده کرده ایم).
بوردهای از پیش ساخته شده ی شرکت Xilinx به طور
خودکار به این نرم افزار شناسانده شده و میتوان از آنها به عنوان Base System
استفاده کرد. با اضافه کردن فایلی با پسوند BST (که دارای
مشخصات بوردها است) میتوان بوردهای غیر استانداردی که به این نرم افزار شناسانده
نشدهاند را، معرفی کرد تا به منظور Base
System مورد استفاده قرار گیرند.
با انتخاب هر بورد به عنوان Base System مشخصات سخت
افزاری بورد از جمله پورتها، میزان Support حافظهها و ...، در پایین wizard نمایش داده میشوند.
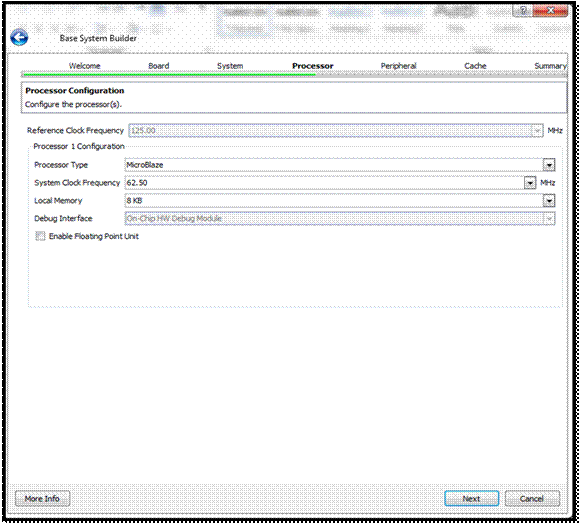
در مرحله ی System تعداد پردازندههای سیستم درخواستی از کاربر پرسیده میشود که به
صورت default
روی گزینه ی Single Processor قرار دارد.
باز زدن گزینه ی Next وارد مرحله ی انتخاب نوع پردازنده Processor میشویم. با در نظر گرفتن توضیحات داده شده در بالا میتوان از انواع Micro Blaze،
Pico Blaze،
Power Pc
و ... استفاده کرد. اما با توجه به نوع بورد FPGA انتخابی در
ابتدای Wizard، این بورد فقط شامل هسته ی پردازنده ی Micro Blaze است. بنابراین نوع پردازنده ای که بخواهیم استفاده کنیم، به نوع بورد FPGA
انتخابی وابسته است که آیا Core پردازندههای مختلف را Support میکند یا خیر. همچنین
مطابق شکل زیر در این مرحله میتوان فرکانس سیستم را انتخاب کرد که با افزایش آن
سرعت سیستم نیز افزایش مییابد اما منابع بیشتری مصرف خواهند شد و زمان سنتز و
ایمپلیمنت نیز افزایش خواهد یافت. علاوه بر آن با انتخاب قسمت Floating Point
دستورات اعداد اعشاری به سیستم اضافه میشود که باعث افزایش زمان سنتز و ایمپلیمنت
خواهد شد.
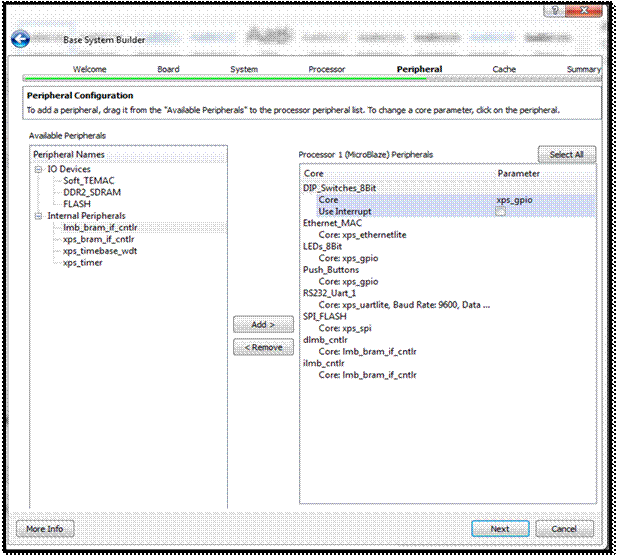
در مرحله ی Peripheral نرم افزار دو جدول را به ما ارائه میکند. جدول سمت چپ Peripheralهای آماده روی بورد را نشان میدهد
(ویژگیهایی که در سیستم وجود دارد) و سمت راست ویژگیهایی است که میتوان به
سیستم اضافه کرد. برای مثال بیان میکند که DIP_Switches_8Bit
از xps_gpio
به عنوان Core استفاده میکند (با فعال کردن Interrupt هنگام
فشرده شدن به پردازنده وقفه خواهد داد). به همین ترتیب انواع مشخصات سخت افزاری را
میتوان به جدول سمت راست Add یا از آن remove کرد. تعداد امکانات سخت افزاری با توجه به ماهیت آنها تأثیر
زیادی در زمان سنتز و ایمپلیمنت کردن سیستم پایه دارد.
در مرحله ی Cache میتوان برای سیستم حافظه ی cache انتخاب کرد که مانند موارد قبلی علی رغم افزایش سرعت سیستم، زمان سنتز
و ایمپلیمنت را افزایش خواهد داد.
در مرحله ی Summary نرم افزار با ارائه ی گزارشی درباره ی سیستم ایجاد شده و آدرسهای
استفاده شده، مراحل ساخت سیستم را به پایان میرساند.
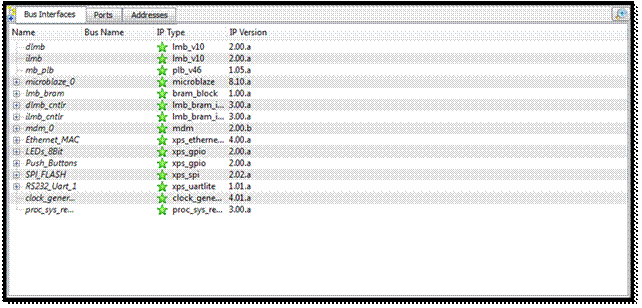
با انتخاب گزینه ی Finish، محیط XPS مشخصات کامل سیستم ساخته شده را از طریق Tabهای Bud
Interface، Port و Addresses
به ما ارائه میدهد. مثلا این که هر Device به کدام باس متصل شده و محدوده ی آدرس آن چیست. به ازای تک تک این
ویژگیها کدهای VHDL ای نوشته شده است که با تغییر آنها کدها به صورت اتوماتیک توسط
نرم افزار تغییر داده میشوند (این کدها در مسیر ساخته شده برای فایل XMP
که در ابتدا کار دادیم، قرار دارند). همچنین با تغییر این مشخصات (مثلا عوض کردن
محدوده ی آدرسها) در صورت بروز خطا نرم افزار پیغام خطا خواهد داد.
نهایتا با تکمیل ویژگیهای سخت افزاری با انتخاب کردن گزینه ی Export Hardware Design to SDK از منوی Project و انتخاب گزینه ی Export&Launch
SDKاز
پنجره ی باز شده، برنامه سنتز و ایمپلیمنت شده و وارد محیط نرم افزار SDK میشویم.
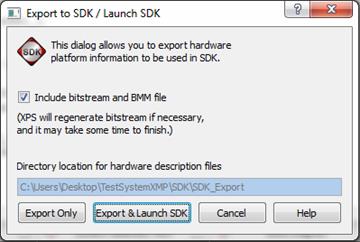
با انتخاب گزینه ی گفته شده، نرم افزار شروع به Export کردن سیستم
برای نرم افزار SDK میکند که زمان مصرف شده ی آن بسته به عوامل
گفته شده در بالا خواهد بود.
با پست سر گذاشتن مراحل Wizard که در بالا گفته شد، در نهایت دو فایل MHS و UCF
ساخته خواهد شد. این یعنی برای انجام بعضی تغییرات (مثل اضافه کردن یک Device
جدید) نیازی به رجوع به Wizard نیست و میتوان تغییرات را مستقیما در این فایلها ایجاد کرد.
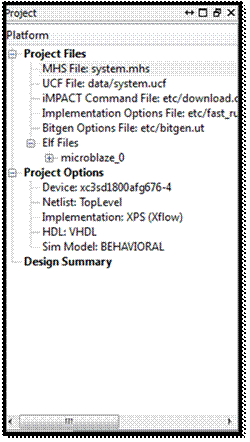
با فایل UCF از قبل آشنا هستیم (Deviceها به کدام پایههای FPGA
متصل شوند). فایل MHS همان اطلاعاتی را که در محیط گرافیکی و Wizard آمده است، در
قالب کد آورده است. قسمت گرافیکی و فایل متنی MHS با هم
ارتباط دو طرفه دارند. این یعنی تغییر در هر کدام موجب آپدیت شدن دیگری میشود.
با اتمام کار نرم افزار XPS، نرم افزار SDK به طور اتوماتیک باز خواهد شد. محیط نرم افزار SDK
همان محیط Eclipse است که به عنوان IDE برای توسعه ی اپلیکیشنها و برنامهها از آن استفاده میشود. فایل
Bit
ساخته شده توسط XPS (که در ابتدای کار به آن اشاره شد در بخش Project Explorer
نرم افزار، در قسمت hw_platform_0 مشاهده میشود).
حال مطابق شکل زیر میتوانیم از محیط نرم افزاری ارائه شده توسط SDK
استفاده و برنامه نویسی نرم افزاری را با ساختن یک پروژه ی جدید آغاز نماییم.
همچنین Template پروژه ی مورد نظر را میتوانیم از Templateهایی که به صورت Default در نرم افزار قرار دارند، انتخاب
کنیم.
در مرحله ی آخر ساخت یک پروژه ی جدید، میبایست Board Support Package
را برای پروژه مشخص کنیم. به عبارت دیگر به توابعی که اجازه ی برقراری ارتباط بین
نرم افزار و سخت افزار را میسر میسازند، Board Support Package یا Driver میگویند. برای ساخت پروژه میتوان این توابع را از اول ایجاد و یا از
در صورت وجود به برنامه Import کرد.
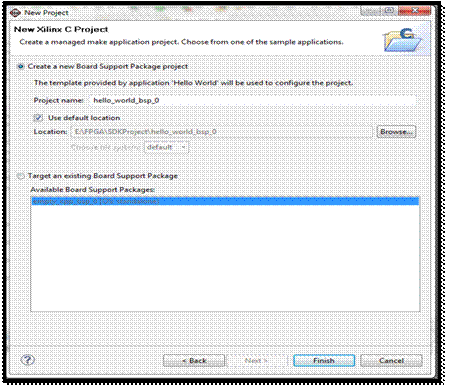
در نهایت با ساخته شدن پروژه، با ورود به قسمت src پروژه و
باز کردن فایل اجرایی برنامه (در این مثال helloworld.c)، برنامههای
خود را به زبان C در آن بنویسم. همچنین با انتخاب گزینه ی Launch on Hardware
از شاخه ی Run as در منوی Run و همچنین اتصال کامپیوتر به FPGA با کابل JTAG،
میتوان برنامه ی نوشته شده را روی بورد پیادهسازی کرد.
 نرم افزار با کامپایل کردن برنامه
ما، فایل نهایی اجرایی به زبان ماشین را در قالب فایلی با پسوند ELF میسازد. این فایل شامل کدهای زبان ماشین است، بنابراین برای اجرا میبایست
در مکانی قرار گیرد (به عنوان مثال این مکان میتواند یک Block Ram
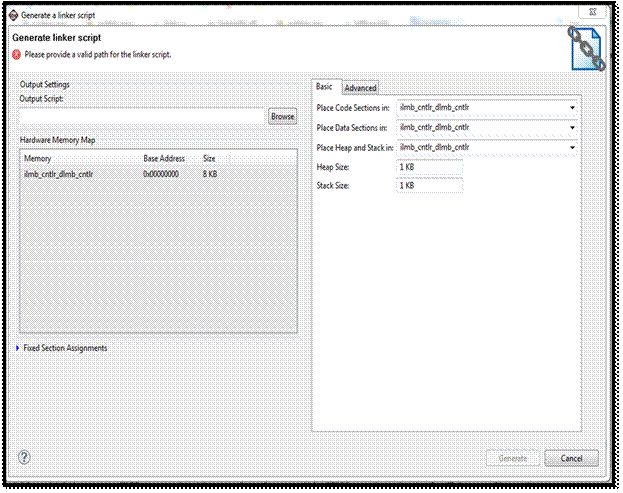
یا حافظه ی DDR که از بیرون به بورد متصل کرده ایم، باشد). برای تنظیم کردن این مورد
و تنظیمات حافظه ای مشابه دیگر، میتوان فایل lscript.ld
(که در قسمت src قرار دارد) را باز و تغییرات را در آن انجام داد. همچنین با
انتخاب Generate Linker Script از منوی Xilinx
Tools میتوان این تنظیمات را از
طریق یک Wizard اعمال نمود.
نرم افزار با کامپایل کردن برنامه
ما، فایل نهایی اجرایی به زبان ماشین را در قالب فایلی با پسوند ELF میسازد. این فایل شامل کدهای زبان ماشین است، بنابراین برای اجرا میبایست
در مکانی قرار گیرد (به عنوان مثال این مکان میتواند یک Block Ram
یا حافظه ی DDR که از بیرون به بورد متصل کرده ایم، باشد). برای تنظیم کردن این مورد
و تنظیمات حافظه ای مشابه دیگر، میتوان فایل lscript.ld
(که در قسمت src قرار دارد) را باز و تغییرات را در آن انجام داد. همچنین با
انتخاب Generate Linker Script از منوی Xilinx
Tools میتوان این تنظیمات را از
طریق یک Wizard اعمال نمود.
در شکل روبرو فایلهای ELF و LD را که توسط نرم افزار ساخته اند را مشاهده میکنید:
1-
با توجه به پیش آگاهی ارائه شده در بخش 9-1، یک پروژه XPS برای بورد
آزمایشگاه ایجاد کنید و از بین Peripheralهای آن فقط پورت UART و کلیدهای
دیپ سویچ و.LEDها را انتخاب کنید.
2-
بیت فایل پروژه ایجاد شده را ایجاد کنید و آن را به محیط SDK منتقل
کنید.
3-
برنامهای به زبان C بنویسید که هرگاه کلید فشرده شده شد،
عبارت a key was pressed را از طریق پورت سریال به کامپیوتر ارسال کند.
4-
برنامه HyperTerminal را در PC اجرا کنید و تنظیمات پورت سریال را روی 9600
تنظیم کنید، سپس برنامهای در SDK بنویسید که وقتی بایتی از طریق HyperTerminal
ارسال میشود، یکی از LEDها را روشن کند.
5-
برنامه SDK را کاملتر کنید تا بتوان توسط برنامه HyperTerminal
شماره LED
ارسال کرد و فقط همان LED روشن شود.